
在外界纷纷期待DeepSeek-R2发布之时,8月21日,DeepSeek小步快跑,宣布发布DeepSeek-V3.1。
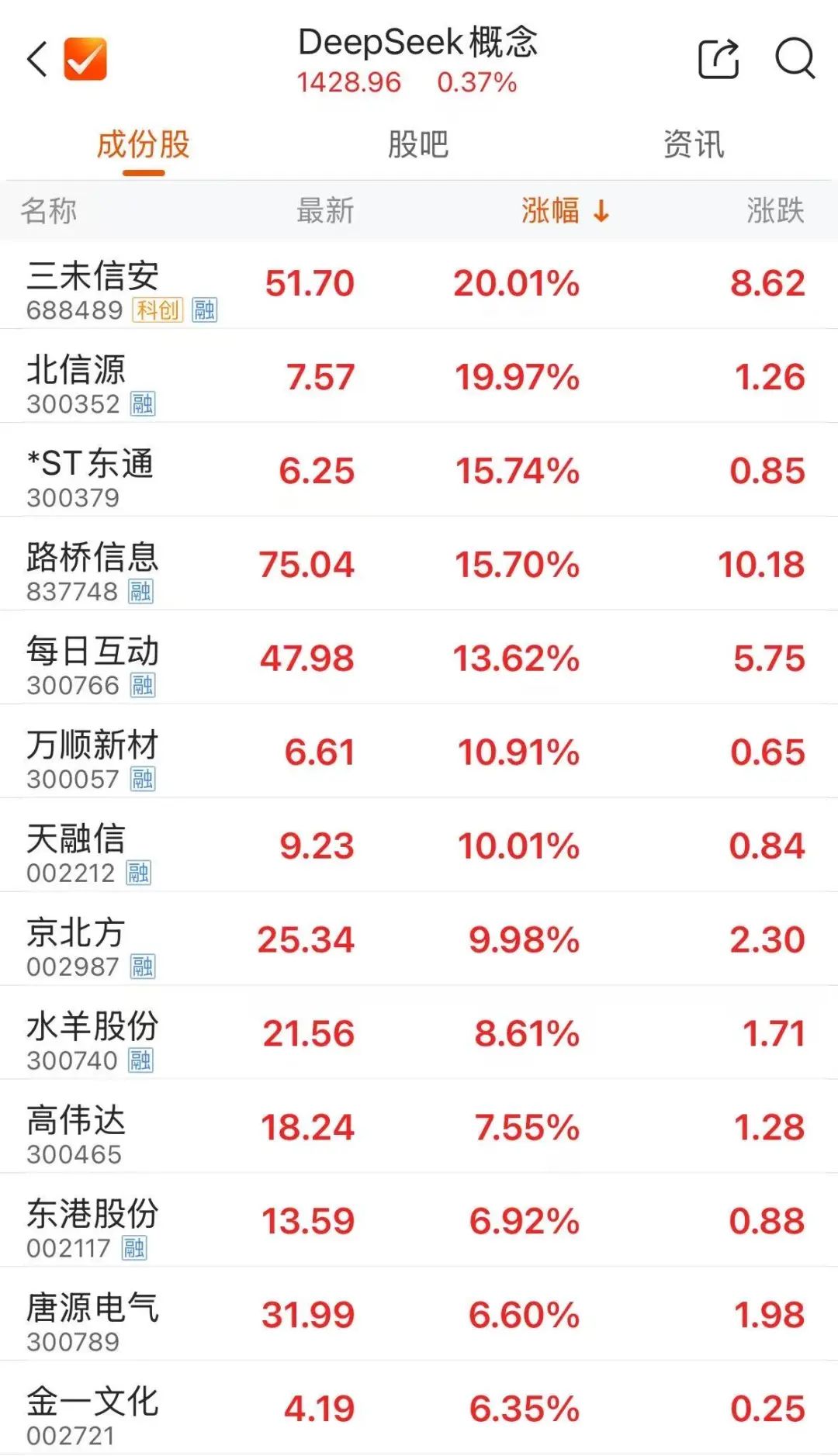
当日,DeepSeek概念板块火热。截至收盘,三未信安、天融信、北信源领涨,路桥信息、每日互动、万顺新材等涨超10%。
此外,DeepSeek宣布涨价。北京时间2025年9月6日凌晨起,DeepSeek将调整开放平台API接口调用价格:DeepSeek-V3.1每百万输入tokens价格分别为0.5元(缓存命中)和4元(缓存未命中);每百万输出tokens由8元提高至12元。此外,DeepSeek原有夜间时段优惠取消。

加速迈向Agent时代
DeepSeek本次更新有何亮点?
据介绍,DeepSeek-V3.1的升级包含以下主要变化。一是实现混合推理架构:一个模型同时支持思考模式与非思考模式。二是更高的思考效率,相比DeepSeek-R1-0528,DeepSeek-V3.1-Think能在更短时间内给出答案。三是更强的Agent能力,新模型在工具使用与智能体任务中的表现有较大提升。
首先,是混合推理架构。据介绍,官方App与网页端模型已同步升级为DeepSeek-V3.1。用户可以通过“深度思考”按钮,实现思考模式与非思考模式的自由切换。DeepSeek API也已同步升级,deepseek-chat对应非思考模式,deepseek-reasoner对应思考模式,且上下文均已扩展为128K。
其次,是智能体支持能力。DeepSeek聚焦热门发展方向编程智能体、搜索智能体展开测评,测试结果显示,DeepSeek-V3.1相较此前模型均有提升。
在编程智能体方面,在代码修复测评SWE-bench(最具代表性的代码修复评测基准之一)等复杂任务测试中,DeepSeek-V3.1相比之前的DeepSeek系列模型有明显提高。
在搜索智能体方面,DeepSeek-V3.1在多项搜索评测指标上取得了较大提升。在需要多步推理的复杂搜索测试与多学科专家级难题测试上,DeepSeek-V3.1性能已大幅领先DeepSeek-R1-0528。
同时,DeepSeek思考效率提升也有所提升。经过思维链压缩训练后,V3.1-Think在输出token数减少的情况下,各项任务的平均表现与R1-0528持平。同时,V3.1在非思考模式下的输出长度也得到了有效控制,相比于DeepSeek-V3-0324,能够在输出长度明显减少的情况下保持相同的模型性能。
此外,本次DeepSeek-V3.1延续了开源这一“惯例”,并且支持更多API格式。在模型开源方面,DeepSeek-V3.1的Base模型在V3的基础上重新做了外扩训练,一共增加训练了840B tokens。Base模型与后训练模型均已在Huggingface与魔搭开源。
同时,DeepSeek增加了对Anthropic API的支持,让大家可以轻松将DeepSeek-V3.1的能力接入Claude Code(一款智能编程工具)框架。
开源热潮持续涌动
对于DeepSeek此次更新,网友们看法不一。
有部分网友认为,本次DeepSeek-V3.1相较于DeepSeek-R1-0528有所提升。同时,Agent的发展已是行业发展共同的命题。本次智能体支持的升级令人看到DeepSeek团队在Agent方向的努力。
不过,也有部分网友称,这次更新不够亮眼。对于此类评价,一位网友戏言,“我们这两个月吃得太好,大家已经变得比较挑剔了。”
在业内专家看来,这段时间以来,模型开源热潮不断涌动,快速迭代的各大模型似乎提高了人们对于模型的认知预期。“卷”似乎成为业内人士对当下大模型现况的共识。
7月底,智谱发布新一代旗舰模型GLM-4.5。据了解,这是专为智能体应用打造的基础模型。8月,智谱推出开源视觉推理模型GLM-4.5V(总参数106B,激活参数12B),并同步在魔搭社区与Hugging Face开源。
阿里巴巴通义千问模型Qwen3动作频频。7月以来,Qwen3模型升级为Qwen3-235B-A22B-Instruct-2507版本和Qwen3-235B-A22B-Thinking-2507推理模型,显著提升了通用能力、用户偏好契合能力及长文本理解能力以及编程、数学等核心能力。Qwen3-30B-A3B模型更新为Qwen3-30B-A3B-Instruct-2507和Qwen3-30B-A3B-Thinking-2507。Qwen3的图片编辑模型(Qwen-Image-Edit)也于8月开源。
阶跃星辰Step 3也于近日正式开源,Step 3的多模态能力围绕“轻量视觉路径”与“稳定协同训练”展开,重点解决视觉引入带来的token负担与训练干扰问题。
此外,7月底,腾讯并开源了发布混元3D世界模型1.0,能够依据文本或图像输入生成沉浸式、可探索、可交互的3D场景。8月,腾讯混元发布四款开源的小尺寸模型,参数分别为0.5B、1.8B、4B、7B,适用于笔记本电脑、手机、智能座舱、智能家居等低功耗场景。
太平洋证券研报称,目前模型后训练阶段仍具备工程红利,基于此国内外大模型持续拓展智能边界,且国内模型在开源领域表现突出,在Hugging Face开源前10榜单中占据不少席位。同时,各基础大模型均实现通用Agent能力提升,“模型即Agent”的范式或正在形成。
