
梁文锋第一次敞开怀抱,引入战投。
5月8日,有消息称,其掌舵的DeepSeek,即将完成首轮融资,投后估值高达500亿美元,约合3400亿人民币。
作为杭州深度求索的创始人,梁文锋的最终受益股份,达到84%。据称,其个人投入或高达200亿元人民币,占募资总额的四成。

融资前夕,他刚“交完作业”。4月24日,DeepSeek-V4上线,距离上一代大版本V3的发布,足足隔了484天。
“DeepSeek被挖走太多人才、高端算力受限。”
一位AI行业资深从业人士向《21CBR》记者表示,这是其转变融资态度、新版本发布推迟的原因。
走下理想国的高塔,梁文锋寻找强援,直面技术创新之外的现实问题。
锚点留人
DeepSeek不差钱。
2025年,其母公司幻方量化的平均收益率,高达56.6%,按照700亿元的管理规模计,对应约400亿元收益,幻方和出资人按行规二八分账,可以提走七八十亿。
有幻方量化作为出资人,为DeepSeek研发输血,资金安全垫厚实。“我们面临的问题,从来不是钱。”梁文锋曾如此表示。
然而,员工个人会有财务的考虑,DeepSeek最聪明的那群人在流失。
《21CBR》记者翻开DeepSeek V4长达58页的技术报告,末尾的作者列表,梁文锋与其他研究员、工程师,近300人并列署名。
10个带星号的名字有些扎眼,标注着“已离职”。
近期出走的技术骨干之一,郭达雅,曾深度参与V3、R1等爆款模型研发,加盟字节Seed,传闻年薪近亿元。
字节方面否认了该说法,补抛了个“钩子”,“不排除有些Seed技术人员,四年后收益会达到数亿元”。
其实,梁文锋开的薪资不低。一名求职者透露,他在2024年面试DeepSeek的深度学习研究员,HR透露薪资能达到150万元。
这位“技术宅”老板,还给了足够多的空间。
一个细节是,DeepSeek的员工通常18点下班,早上不打卡,也没有KPI。源于梁文锋认为,人一天能高质量输出的时间,很难超过6-8小时,创新需要尽可能少的干预和管理。
在AI抢人大战里,梁文锋还需要给团队更多安全感,尤其是,对员工手里的期权,有所交代。
有了外部融资,DeepSeek会有一个公开估值,期权才有定价锚点。这是留人的前提。
梁文锋改变态度,正与国家集成电路产业投资基金、腾讯等机构洽谈。
知情人士称,本轮融资将用于提升计算能力和改善员工福利,以应对激烈的竞争。
算力博弈
人才议题之外,梁文锋还有一场算力的硬仗要打。
《21CBR》记者注意到,截至5月9日,DeepSeek共有36个职位亟待人才,光4月27日,就批量放出了十余个岗位需求。
梁文锋对产品的关注度提升,强化Agent方向的人才招募及探索,同时,开招“搜索算法研究员”。
该岗位职责包括设计面向AGI的新一代通用搜索引擎,负责LLM在搜索场景下的规模化落地。

为了突破算力瓶颈,DeepSeek开始招募“AI超算集群运维工程师”了。
其职责之一,是“负责新一代计算资源的快速交付与上线,确保资源能高质量、高性能地投入生产”。有千卡以上的大规模AI超算集群运维经验,是岗位加分项。
同月开招的,还有“数据中心高级交付经理”“数据中心高级运维工程师”,工作地点在乌兰察布,月薪最高3万元。
梁文锋早在2021年,就颇有先见之明地囤了1万张英伟达A100。
“梁很有情怀,早期手里的卡多,他开放提供给高校,用于科研。”有AI从业者向《21CBR》记者透露。
幻方“萤火一号”
在复杂的芯片格局下,梁文锋及DeepSeek,背负“用国产算力跑国产模型”的巨大期望。DeepSeek一发布,国内做GPU芯片的架构,也开始变了。
V4技术报告里,有一处提到了华为昇腾:团队将细粒度专家并行(EP)方案,同时在英伟达GPU和华为昇腾NPU上完成验证。
“这说明DeepSeek V4的推理路径,已具备跨算力平台的适配能力。”一位AI行业人士称。
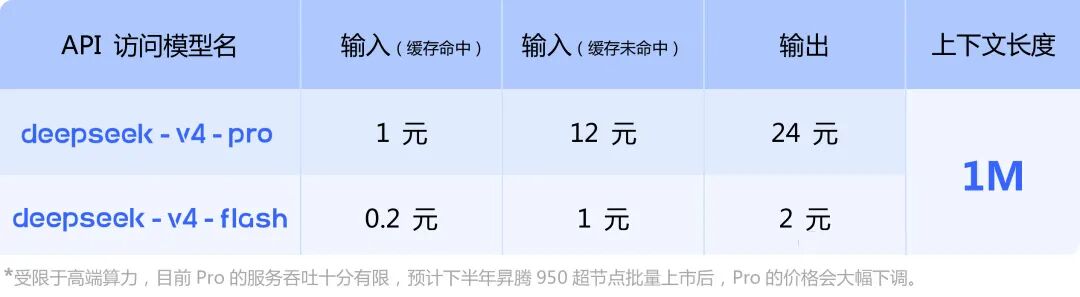
与之对应,DeepSeek介绍V4价格时,一行标灰的图注小字,信息量巨大:
受限于高端算力,目前Pro的服务吞吐十分有限,预计下半年昇腾950超节点批量上市后,Pro的价格会大幅下调。
种种信号,引人振奋。国产算力要完全“顶起来”,仍需时间。
“国产算力目前集中在推理阶段,且限定在容错率高的场景,离吃算力的核心预训练阶段使用,还有段距离。”
有AI行业从业者给出相对保守的估算,“起码八到十年的差距要追赶。”
死磕效率
回到V4本身,它是观察梁文锋模型taste(品味),最直观的出口。
总体来说,关键词没有变:效率。
DeepSeek-V4开创了一种全新的注意力机制——在token维度进行压缩,结合DSA稀疏注意力,实现极强长上下文能力的同时,相比传统方法,大幅降低对计算和显存的需求。
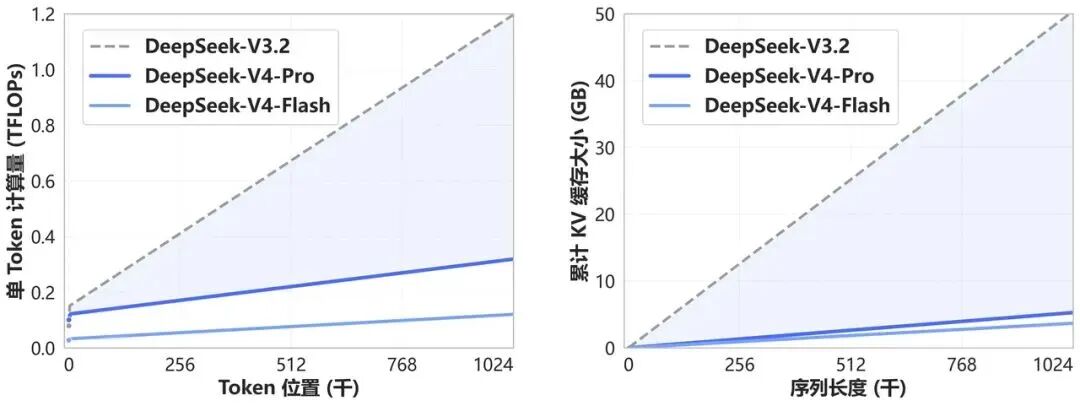
简单来说,它让长文本处理效率,有了质的飞跃。
由此,百万级上下文,以前是闭源旗舰模型才玩得起的“奢侈品”,一下打成“白菜价”。
V4有两个版本,DeepSeek-V4-Pro(专家模式)和DeepSeek-V4-Flash(快速模式)。
前者负责“强”,官方称,性能比肩顶级闭源模型;后者负责“省”,提供快捷、经济的服务。
专项能力方面,梁文锋带队重点攻Agent方向,V4系列针对Claude Code、OpenClaw等主流Agent产品进行适配和优化。
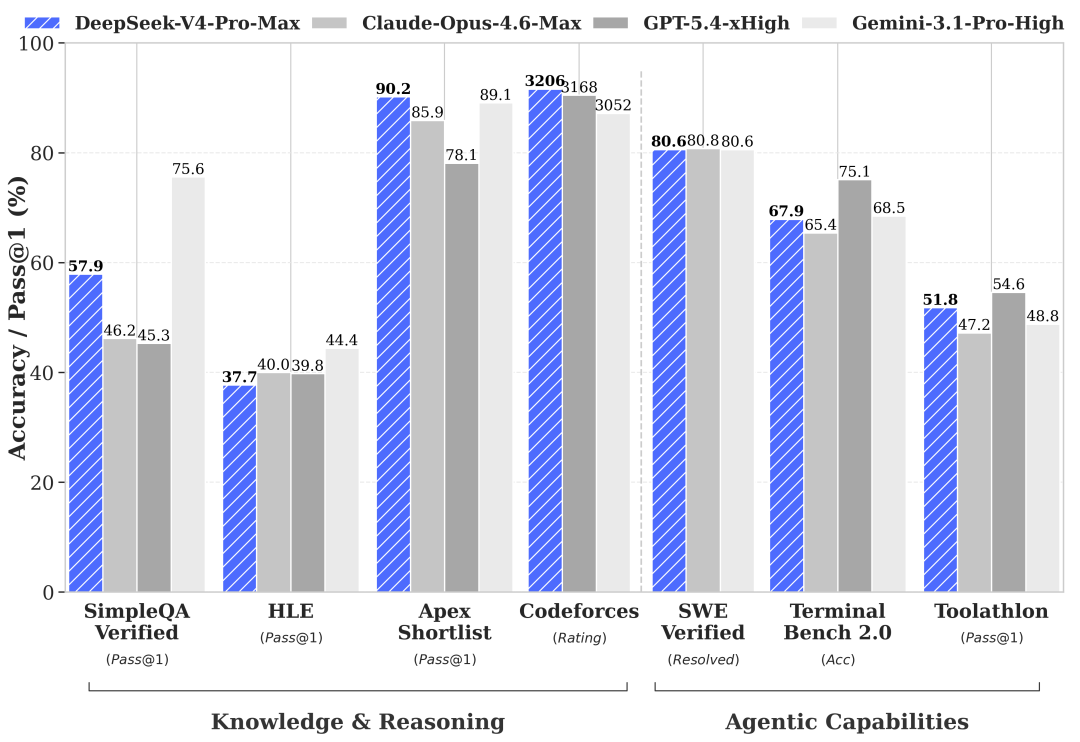
DeepSeek-V4-Pro:性能比肩顶级闭源模型
内部称,在Agentic Coding评测中,V4-Pro已达当前开源模型最佳水平。
“据评测反馈,使用体验优于Sonnet 4.5,交付质量接近Opus 4.6非思考模式,仍与Opus 4.6思考模式存在一定差距。”DeepSeek罕见披露了内部使用Agentic Coding模型的状况。
需要指出的是,DeepSeek此次发的是“预览版”,正式版还要再等等。
“V4的能力水平仍落后于GPT-5.4和Gemini-3.1-Pro,发展轨迹大约滞后前沿闭源模型3至6个月。”在技术报告中,团队坦言。
锚定顶级模型,梁文锋仍执着求解,当算力越来越贵的时候,能否通过极致的架构创新,继续把算力成本砍下来。
“不诱于誉,不恐于诽,率道而行,端然正己。”V4的发布公告里,梁和团队以这样的一句总结,表明初心。
