
偏一点儿就会洒出来;碰到杯沿可能弄翻,让机器人倒一杯果汁,可不仅是“拿起瓶子、对准杯口”那么简单。真正可靠的机器人,最好能在动手之前,能够像人类在脑海里“过一遍”,预判哪种动作更稳妥。5月31日,上海创智学院罗剑岚团队发布开源具身世界模型τ-WM,通过多源异构数据预训练,围绕动作预测、未来状态模拟和部署阶段动作优化,构建了一套完整系统,试图让机器人具备“行动前预演”的能力。
机器人自主完成整理书包任务
听懂指令也要看懂后果
相比大语言模型擅长理解文字,传统控制程序擅长执行固定动作,具身世界模型要解决的是:机器人如何理解“动作改变现实世界”。
罗剑岚解释,它像是给机器人装上一个带有物理常识、能够预测未来画面的“大脑”。“不仅看见眼前有什么,也不只是机械地输出下一步动作,而是能把候选动作放进模型里推演:这样抓会怎样,那样倒会怎样,哪一种更可能成功、更安全。”
以倒果汁任务为例,机器人左手拿杯、右手拿瓶时,可以先生成多种相近动作轨迹。随后,τ-WM仿真器预测这些轨迹对应的未来画面,并进行评分——果汁顺利倒入杯中,评分较高;洒到桌面或撞倒杯子,评分较低。最终,机器人执行分数最高的动作。
对普通用户来说,这意味着机器人不再只是“看见后反应”,而是在“想过后行动”。罗剑岚指出,这也是具身智能走向通用机器人的一个关键问题——机器人不能只会听懂人类命令,还要能判断自己的动作会带来什么后果。
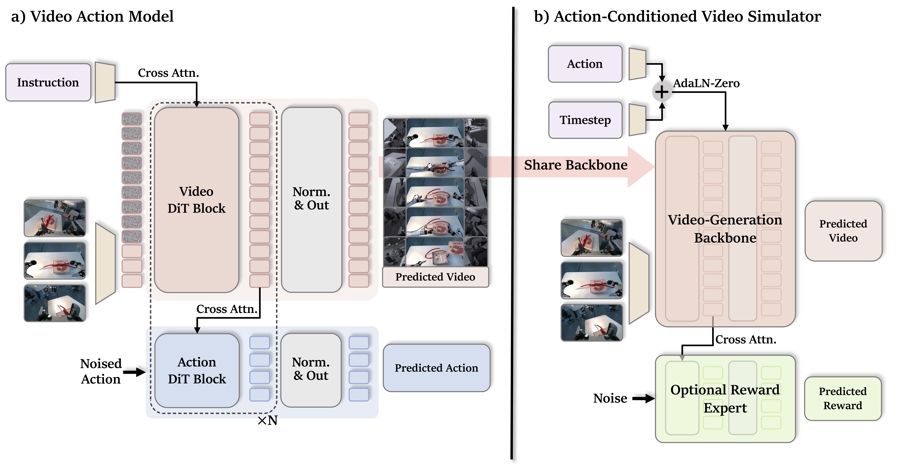
视频动作模型和动作条件视频仿真器
让多种数据一起教机器人
不过,目前机器人训练长期面临“任何单一数据源都不够”的现实困境。真机数据有准确的动作标签,但往往局限在特定机器人本体、任务数量和实验环境中;UMI(通用操作接口)数据由人佩戴头部相机和夹爪,在家庭、商超等场景采集,可以扩大任务和环境覆盖,但与真机动作标签存在差异;第一视角人类视频记录了大量人手操作和物体交互细节,却缺少机器人关节动作;开源机器人数据则来自不同平台和不同构型,格式和规范也并不统一。
τ-WM模型把这些多源异构数据纳入了同一训练框架。据介绍,该模型使用约3万小时多样化数据进行预训练,包括真机数据、UMI数据、第一视角数据等,并通过统一预训练动作空间,让不同本体数据和带动作标签的数据尽可能共同发挥作用。
这意味着,模型不再只是从一种机器人、一个场景、一类任务中学习,而是从多种“身体”、多种环境、多种操作中提炼更通用的物理经验。学习了大量“动作如何改变场景”的视频片段,τ-WM不仅记住动作样子,而且学习物体交互的规律:被推的物体会移动,被碰的物体可能倾倒,被拿起的物体会改变位置。对机器人来说,这类经验正是从演示走向陌生场景的基础。开源也让这项工作具备更强的公共价值,有助于更多团队在同一基础上验证、改进和拓展。

理工具箱、理书包、装水管、收纳羽毛球的四种任务执行步骤拆解
离“可靠机器人”更近一步
“用大规模混合数据训练,让机器人获得更强的未来推演、动作选择和跨任务泛化能力”,罗剑岚认为,τ-WM验证了一条具身基础模型的新路径。
同时,τ-WM已经显示出对环境变化更强的适应能力。灯光、背景、物体纹理发生变化,或物品类型、位置发生变化时,机器人仍能保持较高任务成功率。对于家庭、商超、工厂等真实场景来说,这类变化几乎每天都会发生。
“这并不意味着通用服务机器人已经到来,具身世界模型仍处在快速发展阶段。”罗剑岚强调,τ-WM是预训练基础模型,特点是通用泛化能力,可以支持多类任务,但并不等于已经专精于所有真实场景。距离稳定可靠的机器人,还需要解决大量低频但影响成功率的长尾问题。
这也使τ-WM与团队此前LWD(边部署边学习)研究形成互补。LWD强调“边部署边学习”,让机器人在真实物理世界交互中继续后训练;τ-WM强调“行动前预演”,通过仿真器提前排除低质量动作、降低探索成本。如果说τ-WM让机器人先在脑中试错,LWD则让机器人在真实执行后继续复盘。
