
不久前正式启动A股上市辅导,同时也是港交所上市公司的上海企业MiniMax,昨天(6月1日)再推新一代通用模型MiniMax M3。
M3模型旨在挑战大模型读取长文档、大段代码时“越往后越忘事”,以及算起来又慢又贵的痛点,是国内首个同时具备前沿 Coding(编程)能力、1M(兆)超长上下文、原生多模态三项核心能力的大模型。上述“三合一”能力很容易引发业内推测——M3正是对标美国Anthropic公司于今年4月推出的Claude Opus 4.7。Opus 4.7主打极致的指令遵循、高清视觉、深度推理及专业代码能力。当下,MiniMax M3不能说能力已超越Opus 4.7,但胜在开源策略与性价比优势。
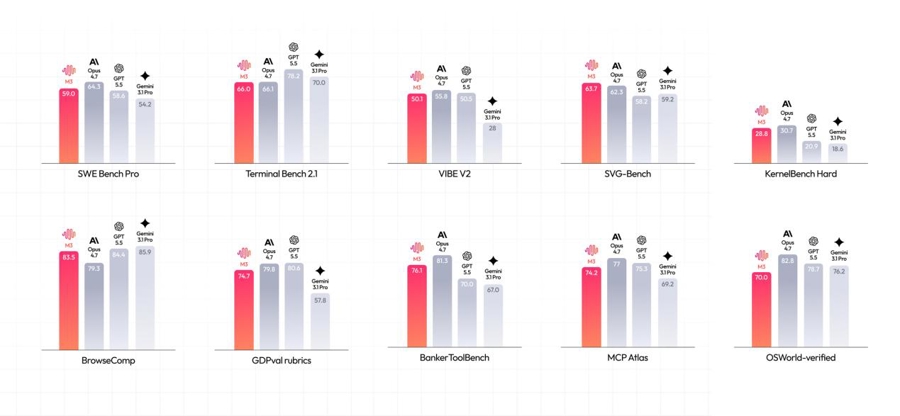
开源的M3,能力逼近Claude Opus 4.7。
具体来看,在衡量编程能力的SWE-Bench Pro评测基准中,MiniMax M3超过OpenAI的GPT-5.5和谷歌的Gemini 3.1Pro,逼近Opus 4.7。
不同于大量模型是在后期才加上看图、看视频的能力,M3从训练的一开始,就实现文字、图片、视频等多模态混合训练,体现出“原生多模态”的属性。
全球大模型竞争正酣,各家公司保持优势的关键能力,在于当Agent(智能体)的任务复杂度不断提高时,模型如何实现更长上下文、更稳定记忆,以及更低成本推理。
据了解,支撑M3保持优势的关键技术底座,在于MiniMax公司自研的稀疏注意力架构MSA(MiniMax Sparse Attention)——相较传统“全注意力机制”,MSA能显著降低长上下文的计算成本,并将上下文窗口提升至100万token(词元),相当于2本中文长篇小说。这意味着,模型在处理长文档、复杂代码仓库、多轮任务协作等场景时可保留更完整的信息链路。关键在于,MiniMax的模型性价比依旧能打,M3的单token计算量仅为上一代模型的约二十分之一。
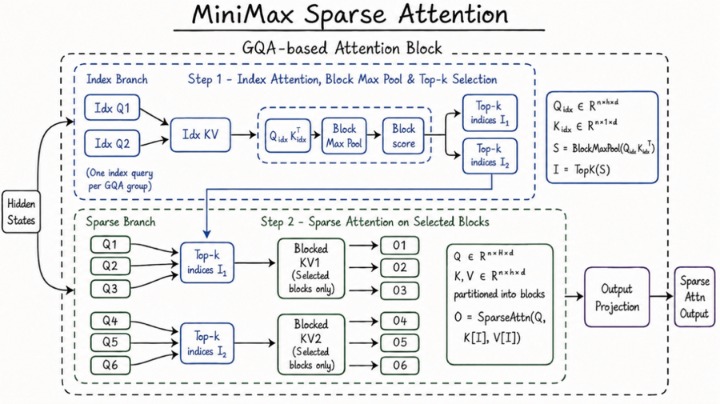
MiniMax公司自研的稀疏注意力架构MSA。
AI行业的终极竞争,在于智能能力的进步速度。MiniMax M1于去年6月发布。去年四季度,公司又密集发布M2和M2.1模型。M2.5则于今年2月发布。此次再发M3,足见上海大模型公司的研发效率。
