
21世纪经济报道记者雷晨
中国信通院近期的一组数据显示,今年一季度,国内AI算力需求同比增长417%,供给增速却仅为128%。供需缺口持续拉大,算力市场量价齐升的表象之下,一个更本质的行业症结正浮出水面。算力集群的规模越建越大,数据供给却接不上节奏。
中科曙光北京公司副总裁何振6月25日对记者表示:“当前,行业发展的瓶颈逐渐从‘算力不足’转向‘数据无法持续供给’。”GPU算力的迭代速度远远跑在数据供给前面。训练阶段数据吞吐波动明显,“checkpoint”写入与恢复耗时漫长,多任务并发访问下资源争用持续加剧,算力空转已经成为全行业普遍存在的痛点。
存储系统的表现直接决定了GPU能否持续获得稳定的数据供给,GPU一旦进入等待状态,每秒都在消耗的算力投入就成了沉没成本。
在ISC 2026高性能计算大会最新发布的IO500榜单上,中科曙光ParaStor F9000全闪存储系统在生产型全节点与10节点两大榜单中均位列第一。
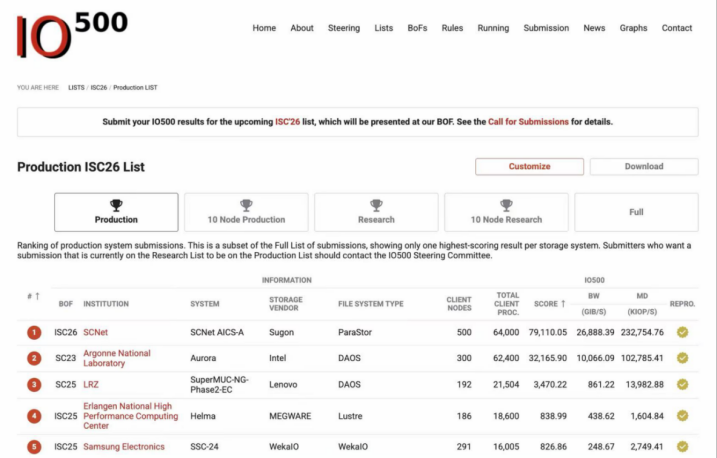
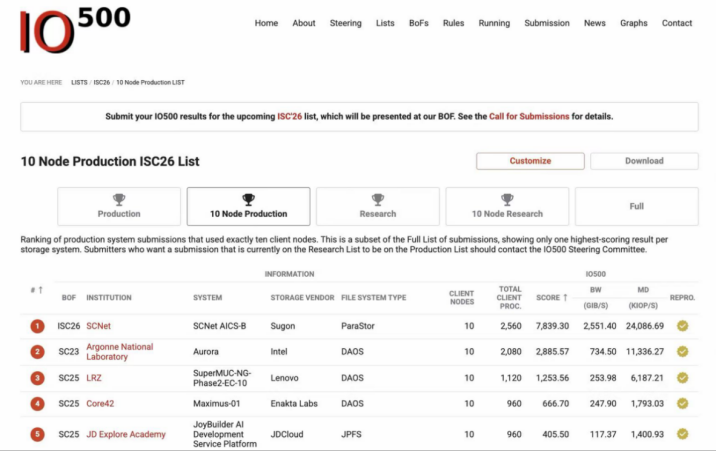
与实验室环境下追求极限峰值的性能测试不同,IO500生产型榜单要求参评系统必须在真实业务环境中长期运行,具备实际负载承载、冗余设计与持续稳定运行能力,部署周期通常以年为单位计算。
何振透露,目前ParaStor F9000已经在数万卡规模集群中稳定运行超过一年。自今年2月国家超算互联网核心节点启动建设以来,这套系统持续投入生产环境并保持迭代优化,稳定支撑大模型训练、科学计算与数据分析等核心场景。
国产存储行业过去长期处于对标国际先进水平的追赶阶段,这次榜单结果显示出,在真实AI基础设施体系中,国产存储已经开始在关键能力维度领先。
这一变化的背后,是AI工作负载正在根本性改写存储系统的角色定位。大模型训练中的“KV Cache”“向量检索”等场景,形成了高频、小IO、强并发的特殊访问模式,传统存储系统的架构设计并未针对这类新型负载做针对性优化。
具体来看,存储系统通过数据路径优化与智能编排,将高频访问数据前移到更高效的访问通道,让GPU不再陷入等待数据的状态,同时将部分轻量数据处理与访问逻辑下沉到存储侧,减少数据在计算链路中的无效搬运与重复计算。
这种角色变化,在具身智能和智能网联汽车等新兴场景中体现得尤为明显。
中科曙光北京公司总裁助理、分布式存储产品部总经理石静观察到:“存储系统正在从传统的‘容量型基础设施’向‘面向AI工作流的数据引擎’演进。具身智能机器人在训练与迭代过程中,持续产生视觉、触觉、运动控制等多模态数据,不仅规模庞大,还呈现出强时间关联性与高频访问特征。”
智能网联汽车的数据链路更长,从车端采集、云端回传、清洗标注、模型训练到仿真验证,形成完整的数据闭环。每日TB级的路采数据,对存储的持续写入能力、冷热数据分层能力以及跨阶段数据调度能力提出了更高要求。
与此同时,存储市场正经历漫长的涨价周期。在受访者看来,AI算力需求爆发后,存储、网络、算力同步扩张带来系统性成本上升,客户面临的核心问题也已经发生本质变化。何振指出:“当前客户面临的核心矛盾已经不是买不买存储,而是如何用同样的预算支撑更大的算力和数据规模。”
在此背景下,智算中心的基础设施规划逻辑也需要被重新审视。“算力强、存力弱、网络不均衡”的行业通病,根源在于资源规划方式仍沿用传统高性能计算或通用数据中心的模式,没有适配大模型时代的数据流动特征。存储、计算、网络各自独立扩展,很容易出现算力等待数据、存储带宽闲置、网络突发拥塞等资源错配问题,最终表现为整体资源利用率偏低。
何振判断,未来几年,全球高端存储市场将呈现几个明确趋势:AI驱动成为主导需求,系统级优化能力的重要性超过单点硬件性能,存算网协同能力成为核心竞争维度。
