
想象一下这样的日常:你坐进驾驶座,目的地已在云端同步。车辆自主驶出地库,流畅汇入晚高峰车流。当路边突然冲出一个骑自行车的行人,车身迅速微调方向、轻点刹车,提前半秒避让险情。
更细节一些:车辆搭载的智能驾驶辅助系统能通过道路上的持续动态,预测前方路面的风险,调整车速和底盘姿态。
这一切,不再只是智驾模型通过感知当下而做出的行为,而是基于对物理世界的深度推演。让智能驾驶拥有这种“预判与推演”能力的核心,正是世界模型。
它通过超大规模融合多模态数据,包括数百万公里真实路况、仿真场景与交通规则,构建出一个动态、可推理的数字化交通世界。车辆不再仅仅“看到”障碍物,更能理解“为什么”。

(图源:华为官网)
简单来说,世界模型让车拥有了“预判的脑子”,而不只是“反应的眼睛”。这一能力,正逐步落地成为现实。
今年4月,华为乾崑推出了全新升级的ADS 4系统,标志着高阶辅助驾驶进入全新阶段。它背后依托的,正是华为乾崑自研的WEWA架构(World Engine & World Behavior Architecture):包含云端的世界引擎(WE)与车端的世界行为模型(WA)。其中WE负责海量数据训练与场景生成,WA则实现车端的实时环境推理与拟人化决策。
不独华为,在2025年,包括小鹏、商汤等在内的科技公司,都已将世界模型视为实现自动驾驶的必经之路。
今年9月,华为乾崑智驾ADS 4将陆续上车。这次大规模上车的背后,世界模型量产上车风潮有望再起,智能驾驶核心逻辑正发生转变:系统不再仅仅学习人类驾驶行为,而是开始理解物理规律本身。
自动驾驶的目标,不再只是学习“人类怎么做”,而是开始思考“怎样做更好”,让驾驶更安全。
端到端之后,智驾寻找“世界模型”
从依赖算力、规则驱动,到引入端到端模型,智能驾驶技术演进至今,一些根本挑战仍未彻底解决。
2024年,在特斯拉技术路线的催化与主机厂“无图开城”战役陆续收尾之后,行业迅速调转方向,集体驶向“端到端”。但越来越多玩家意识到,传统的端到端模型并非完美解药——它极度依赖高质量、大规模的真实驾驶数据去做行为“克隆”,本质上是在“模仿人”,而非真正理解物理世界或实现认知跨越。
举例来讲,现实道路上如果90%的司机在复杂路口选择刹车观望,仅有10%能够流畅通过,这时候智驾系统更可能学会的是“保守停车”而非“精准决策”。它不辨别行为对错,只模仿概率分布;不追求最优解,只拟合常态。
训练这样一个模型,你很难指望它自然“学”成顶尖高手,更可能的结果是开得越来越像一个“平均水平的司机”——犹豫、保守,甚至继承了人类驾驶行为中所有的常见缺陷。
在人工智能领域,端到端模型符合典型的Scaling Law(规模法则)特性:模型性能随数据量、参数规模和算力增长而提升,且尚未见顶。数据越多、模型越大、算力越强,它的驾驶表现就越拟人、越流畅。
但Scaling Law的另一面是,它无法超越数据本身的品质与分布。有哈佛等院校的研究人员曾在去年发布的一篇论文中指出,低精度训练会降低模型的“有效参数量”。
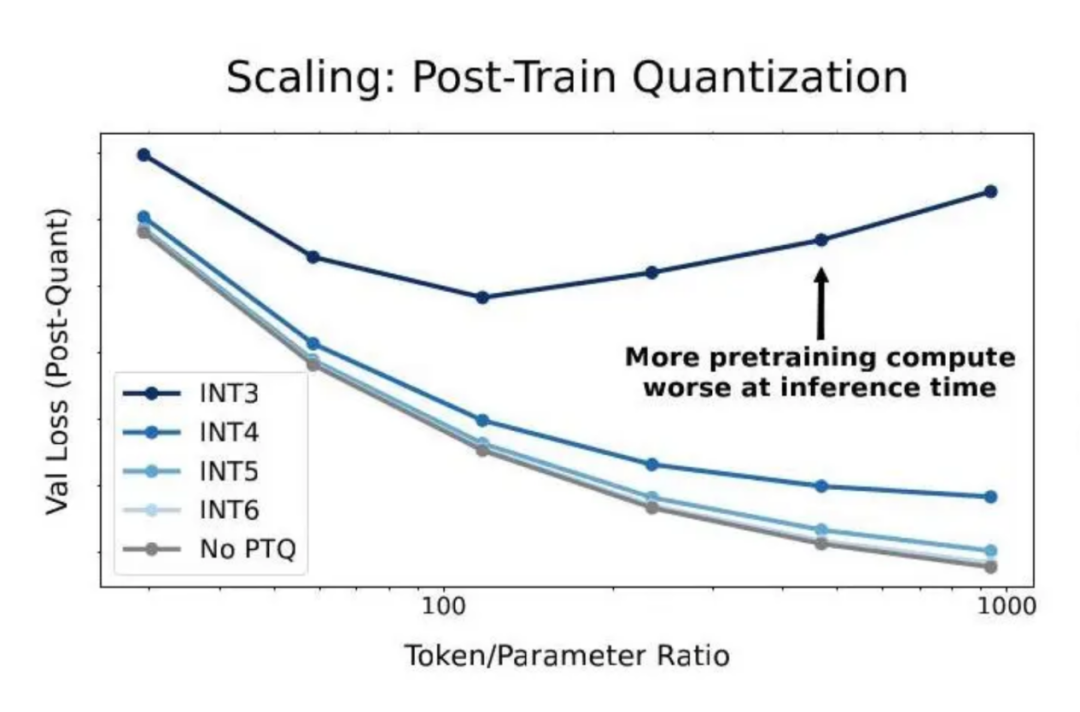
(图为论文《scaling law for precision》中提出的研究量化图,在训练后期,用的训练数据越多,量化之后模型性能下降得越厉害)
也因此,面对真实世界中层出不穷的罕见场景,端到端模型依然会暴露泛化能力的天花板。在此背景下,行业不再争论“要不要转向端到端”,而是探求如何实现“更安全的自动驾驶”。
世界模型就是在这样的背景下诞生的。2025年伊始,主机厂和智驾供应商们正在做一道关于自动驾驶技术路径的选择题:
选项A是彻底抛弃模块化设计、直接采用“一段式”端到端,或保留感知决策层、规划控制层模块,进行“两段式”端到端方案;
选项B是引入视觉语言模型(VLA/VLM),尝试用多模态大模型重构整个驾驶交互逻辑;
选项C则是加入世界模型,让系统学会理解、预测并推理物理世界的运行机制。
世界模型之所以被推至台前,根本上是为了解决端到端模型“只会模仿、不会思考”的瓶颈。
它的思路并不复杂:不再仅仅依靠人类驾驶数据去“模仿”,而是尝试让AI真正理解驾驶环境、预测未来变化,甚至自主生成合理的行为链,靠的是融合深度学习与思维链(CoT)推理框架。这种架构能够自主生成连续推理链条,逐步突破长思维逻辑的局限,从而大幅提升复杂环境中的判断能力。
在此程度上,世界模型不仅解决了训练数据稀缺和质量不均的问题,更打开了模型能力的天花板。
在智驾路线的“大迁徙”中,整个智驾供应商的排名也大有变化,但华为乾崑依旧是稳居第一梯队的那位。根据佐思汽研发布的调研数据,2024年,在国内三方前装辅助驾驶域控全栈软硬一体方案市场中,华为乾崑以79.0%的绝对市场份额稳居第一。

(图源:佐思汽研)
华为乾崑之所以能持续领跑,不在于盲目追随技术热点,而在于其围绕驾驶本质,走了一条更底层、更专注空间推理的路径。2025年4月,华为乾崑在第一梯队智驾供应商中率先发布了基于世界模型的乾崑智驾ADS 4系统。9月起,乾崑智驾ADS 4将开始陆续推送。
真正体现出华为乾崑差异化的,是在行业热议“端到端”和“VLA(视觉语言模型)”路径时,它始终走自己的路。
以VLA为例,这类方法尝试在自动驾驶系统中引入大语言模型,将视觉信号先转成文本描述,再推理成驾驶动作。它优势明显:理解路标、交规等语义信息更加轻松,也容易复用现成的大模型技术。
但华为乾崑看到其短板:语言模型擅长文本推理,却缺乏对三维空间的精确感知与运动推演能力。而车,毕竟是在真实空间中运动的物体,毫厘之差可能就意味着风险。
“华为不会走向VLA的路径。我们认为这样的路径看似取巧,其实并不是走向真正自动驾驶的路径。华为更看重WA(世界行为模型),也就是world action,中间省掉language这个环节。”华为智能汽车解决方案BU CEO靳玉志说。
在2024年华为联合浙江大学发布的一则论文中,华为就提出了Drive-OccWorld,这是一种以视觉为中心的世界模型,能够借助世界模型所具备的“记忆”与“推演”能力——积累环境知识、预测未来状态,从而提升自动驾驶系统的规划表现,进一步增强端到端规划的安全性与稳健性。
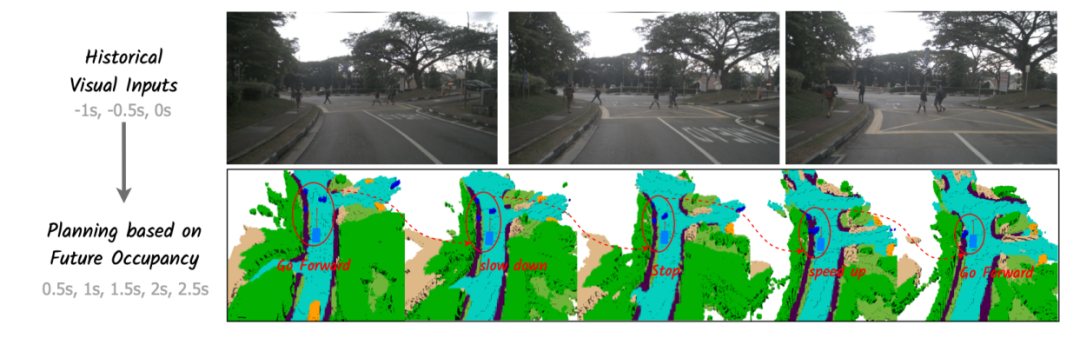
(本图展示了行人横穿马路场景下,世界模型依据前三帧历史图像(上图),对未来两秒的占据状态进行的动态预测(下图)。红色圆圈标示出了场景中的显著移动物体。图源:华为联合浙江大学发布的《Driving in the Occupancy World: Vision-Centric 4D Occupancy Forecasting and Planning via World Models for Autonomous Driving》)
用更系统的模型设计,重塑智驾天花板
业界实践也在表明,世界模型已成共识。
2023年,特斯拉在当年的CVPR2023上就已经展示了其世界模型的研究动态,但当时研发尚处于初期,马斯克推崇的也是扩散模型diffusion。此前有观点认为,Diffusion模型逐步refine预测的过程,可能更接近人类的认知和创造过程,比一些一步到位的生成方式更有潜力。

(图源:X平台)
在中国市场,蔚来和小鹏则是目前主要在实践世界模型的主机厂。2024年,蔚来发布了中国首个智能驾驶世界模型NWM(NIO World Model),蔚来的世界模型具备多模态自回归特性,能够在100毫秒内推演出216种可能场景/轨迹。
小鹏依赖的是海量算力和数据训练驱动高阶智驾。目前,小鹏设计的是云端大模型(即世界基座模型)和车端小模型并进的路子。云端大模型负责“强化学习”和知识创造,车端小模型将知识转化为瞬间的驾驶决策。在小鹏的云端大模型中,LLM(大语言模型)是其骨干,其VLA路径需将视觉等信息转换成语言的token进行训练,再生成控制动作。
与它们相比,华为乾崑的模型架构与众不同,反而选择一条摆脱了语言中介的、更稳妥、却也更为系统的路。
其核心创新,是构建了“云端世界引擎(WE)+车端世界行为模型(WA)”的双层认知架构。前者致力于高效生成和迭代极端场景,实现“以AI训练AI”;后者则融合多模态感知信号,实现实时推理与拟人化控制——相当于为智能驾驶系统装上双重大脑。

(图为华为的WEWA架构)
在云端,华为乾崑依托自研的生成式模型,专注于自动驾驶中最稀缺的极端场景生成。
生成用于训练的场景最基础且重要的在于场景的真实性,行业普遍采用的Diffusion Transformer或3D高斯散射(3DGS),固然能生成丰富图像和3D场景,但仍面临“好看不一定好用”的问题——生成的数据是否合乎物理规律、能否精准覆盖系统薄弱环节,才是关键。
华为乾崑的差异化在于两点:一是生成“难题”,自研生成模型不强求通用能力,而是专注Corner Case,如突然横穿的行人、暴雨中的滚动障碍物,采集难以获得的高价值场景;二是闭环真实,通过严格算法校验,确保合成场景的光照、材质、运动符合真实世界物理,不让有缺陷的仿真数据污染系统认知。
简单来说,华为乾崑WE的本质,是用AI给智驾系统“出难题”,而且出的是“真难题”,从而系统性地锤炼出一套更稳健、更安全的驾驶能力。
为了兜底安全,华为乾崑也云端设计了一套奖惩函数——Reward奖惩函数,以训练模型的安全、合规、可靠且符合人类价值观的决策和行为能力。
在车端,与行业普遍采用“用语言大模型改造智驾模型”的思路不同,华为乾崑的世界行为模型(WA)选择了一条更专注、更高效的路径:它是从零开始训练的、专为智能驾驶而生的行为模型。
靳玉志透露,WA就是直接通过行为端,或者说直接通过vision这样的信息输入控车,这里的vision只是一个代表,它可能来自于声音,可能来自于vision,也可能来自于触觉。
关键在于“专用”而非“复用”。语言大模型虽然文本推理能力强,但缺乏对空间、距离、速度的本体感知,把驾驶决策交给它,好比让一位语言学家去学开车——他虽然能读懂交规,却很难瞬间判断刹车距离或障碍物方位。
这意味着,华为乾崑的WA模型不一定参数规模最大,但它一定最懂“车该怎么开”——它专为安全行驶而来,不为流畅对话而生。

(图源:华为官网)
除了模型架构,华为乾崑在智能驾驶领域还拥有一个更为直观的竞争优势:规模庞大的真实车队,使其规模化落地方面步伐更快。
靳玉志近日宣布,乾崑智驾系统的搭载量已突破100万辆,覆盖包括东风、长安、广汽、北汽、比亚迪、赛力斯、奇瑞、江淮在内的11家车企、28款车型,未来新上市的车型还包括问界新M7、尚界H5、广汽传祺向往S9等。目前,华为上车的速度还在加快,靳玉志透露,华为乾崑智驾方案目前匹配一款车型最快仅需6至9个月。
这支百万量级的“智能车队”中,每一辆车都在实时反馈复杂场景:
数据持续流向云端,经过世界引擎(WE)的筛选、重建和增强,生成更有效的训练场景,迭代出更可靠的驾驶模型。
与此同时,车端的世界行为模型(WA)同步发挥着“实时推理引擎”的作用,它接收云端下发的优化模型,在本地融合多模态感知数据,再对周围环境进行精准理解与秒级决策。
新模型再通过OTA迅速部署回车端,推动全车队整体进化——华为乾崑借此构建了一个“感知-云端训练-车端进化”的自主进化闭环。
这一能力闭环,也为华为乾崑迈向更高阶自动驾驶铺平道路。它不只支撑现有的L2+系统优化,更在为L3及以上级别的自动驾驶做准备。规模化的真实数据、专用化的世界模型,加上清晰一致的技术路线,共同构成华为乾崑在智驾竞赛中最坚实的护城河。
