
被称为“价格屠夫”的DeepSeek再次挥刀降价了。
9月29日晚间,DeepSeek宣布正式发布 DeepSeek-V3.2-Exp模型,性能仍是稳步提升,但出乎意料的是,调用价格大幅降低,尤其输出价格大降75%,业界人士表示“这很难卷得过”。DeepSeek提到,在新价格政策下,开发者调用DeepSeek API的成本将降低50%以上。

具体来看,输入价格上,缓存命中时,DeepSeek-V3.2-Exp从0.5元/百万tokens降至0.2元/百万tokens,缓存未命中的价格则从4元/百万tokens降为2元/百万tokens;输出价格上,从12元/百万tokens直接降到了3元/百万tokens。
降价原因方面,DeepSeek介绍是得益于新模型服务成本的大幅降低。V3.2-Exp是一个实验性(Experimental)的版本,作为迈向新一代架构的中间步骤,在 V3.1-Terminus 的基础上这一模型引入了 DeepSeek Sparse Attention(一种稀疏注意力机制),针对长文本的训练和推理效率进行了探索性的优化和验证。
简单来说,因为实现了细粒度稀疏注意力机制,在几乎不影响模型输出效果的前提下,可以实现长文本训练和推理效率的大幅提升。
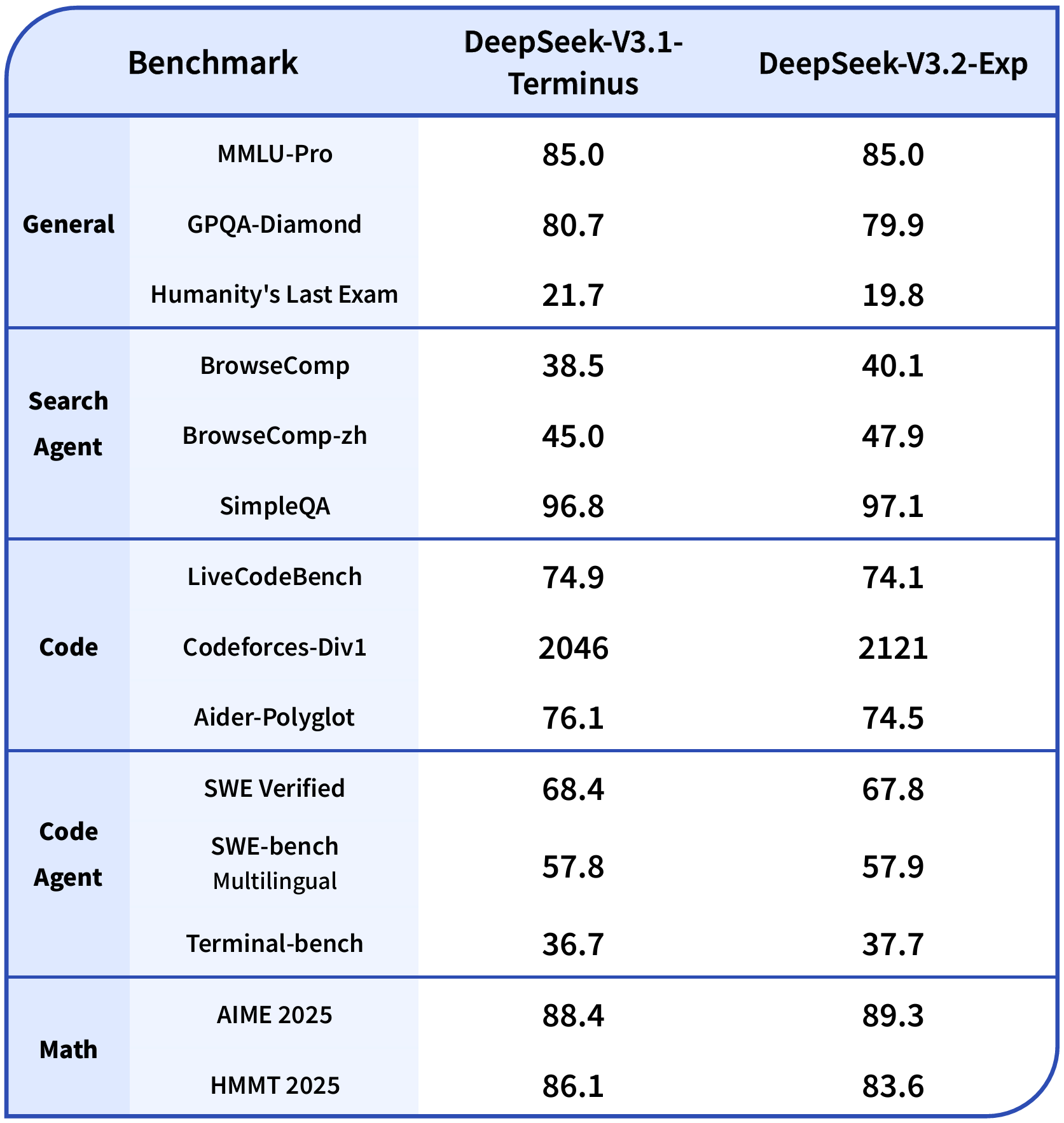
DeepSeek介绍,为了严谨地评估引入稀疏注意力带来的影响,团队将 DeepSeek-V3.2-Exp 的训练设置与 V3.1-Terminus 进行了严格的对齐。在各领域的公开评测集上,DeepSeek-V3.2-Exp 的表现与 V3.1-Terminus 基本持平。
目前,DeepSeek-V3.2-Exp 模型已在Huggingface与魔搭开源,官方App、网页端、小程序均已同步更新为DeepSeek-V3.2-Exp。API 的模型版本已经更新为 DeepSeek-V3.2-Exp,访问方式保持不变。
此外,为支持社区研究,DeepSeek 还开源了新模型研究中设计和实现的 GPU 算子,包括 TileLang 和 CUDA 两种版本。团队建议社区在进行研究性实验时,优先使用基于 TileLang 的版本,以便于调试和快速迭代。
值得一提的是,就在9月22日,DeepSeek才发布了DeepSeek-V3.1-Terminus模型,Terminus在拉丁语里是终点、界限的意思,当时业界猜测这是否会是V3系列的终极版本,并期待下一个发布的将是大版本更新,目前看起来这个猜测并不成立。
在年初海内外出圈后,DeepSeek每一次更新都成为业界瞩目的焦点,但这几个月以来DeepSeek几次更新都是小版本的迭代,关于V4和R2的呼声也越来越多。在DeepSeek这次 X平台上的官宣帖子下,就有海外网友询问“什么时候可以期待下一个V4和R2的版本”,很快有网友回复表示,结合这次发布来看近期并不会看到。
