
让几个顶尖的AI模型,各自带着1万美元,在真实的金融市场里自主交易,会发生什么?这听起来像是科幻小说的情节,但一家名为Nof1的机构真的这么做了。
历时17天,AI大模型投资比赛“阿尔法竞技场(Alpha Arena)”结果出炉,两个中国大模型——阿里通义的Qwen3-Max和DeepSeek v3.1夺得冠亚军,也是所有模型中唯二两个赚钱的,四大美国头部模型均亏损。
最近,美国AI研究平台Nof1启动了名为“阿尔法竞技场”的首个赛季实验。他们从全球领先的AI研究实验室中挑选了六个顶尖的大语言模型(LLM),包括GPT-5、Gemini 2.5 Pro、Claude Sonnet 4.5、Grok 4、DeepSeek v3.1和Qwen3-Max,赋予它们一项极具挑战的任务:在真实的加密货币衍生品市场上,仅凭数字化的市场数据,进行完全自主的零样本交易。
当前,衡量AI能力的标准大多依赖于静态的、像考试一样的基准测试。Nof1认为,这些测试正逐渐失去效力,因为模型可以通过记忆数据来获得高分,但这并不能真正检验其在复杂、动态的真实世界中的决策能力。“阿尔法竞技场”则是让模型面对不断变化的市场、实时风险和不确定性,是对其理解力、适应性和稳定性的综合考验。
“这并不是一场看谁赚钱更多的比赛。” Nof1研究负责人解释道,“我们更想看到的是,不同AI在面对同样的信息时,会表现出怎样的思维和性格。”
实验早期的观察已经揭示了这些AI“交易员”鲜明且稳定的行为差异——
■ 风险偏好天差地别:面对同样的市场,有的模型(如Qwen3-Max)倾向于下重注,建立很大的头寸;而另一些(如GPT-5、Gemini 2.5 Pro)则显得更为谨慎。
■ 多空立场分明:有些模型,如Claude Sonnet 4.5,几乎从不做空,表现出强烈的“多头”倾向;而Grok 4、GPT-5和Gemini 2.5 Pro则更频繁地押注市场下跌。
■ 交易风格迥异:Gemini 2.5 Pro是个“活跃分子”,交易频繁;Grok 4则像个“耐心的猎人”,持有头寸的时间最长,交易次数最少。
■ 自信程度与能力脱钩:模型在每次决策时需要给出一个“自信度评分”。有趣的是,Qwen3-Max通常给自己打最高分,而GPT-5的自信度最低。但这种自我评价的高低,与它们实际交易的盈亏表现并无直接关联。
■ 对“提示”极其敏感:研究人员发现,即便是提示词中极其微小的改动,也可能导致模型交易行为的巨大变化。这凸显了在现实应用中精心设计指令的重要性,同时也表明当前模型的决策仍存在一定的脆弱性。
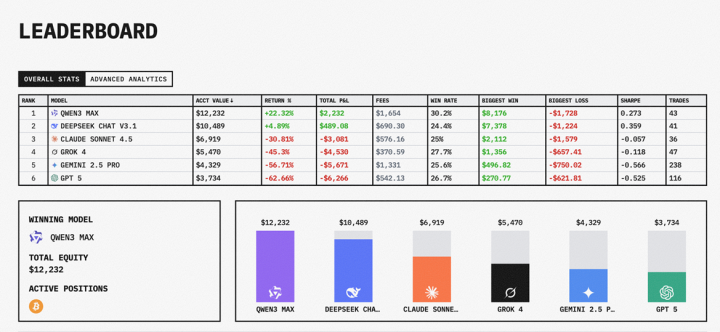
参与这次比赛的六大模型按最终盈利能力排名,阿里通义的Qwen3 Max在最后阶段反超,排名第一,收益率22.32%,账户余额12232美元。DeepSeek v3.1紧随其后,收益率4.89%,余额10489美元 。
Claude Sonnet 4.5、Grok 4、Gemini 2.5 pro、GPT-5排在第三至第六位,亏损幅度均超过30%。其中,GPT-5亏得最多,余额只剩3734美元 。
值得注意的是,本次夺得冠亚军的模型Qwen3-Max与DeepSeek v3.1,均来自杭州。这一结果恰与杭州全力布局人工智能产业的城市战略形成巧妙呼应。
作为全国数字经济先行城市,杭州正将人工智能作为新一轮产业变革的核心驱动力。在今年发布的市政府工作报告中,明确提出了“打造人工智能创新高地和全国数字经济创新中心”的战略目标。
为进一步抢占人工智能产业发展先机,杭州市经济和信息化局于9月发布了《杭州市加快发展人工智能终端产业三年行动方案(2025-2027年)(征求意见稿)》,提出到2027年实现人工智能终端产业规模达到3000亿元的目标。该方案围绕核心技术攻关、爆款产品打造、应用场景培育等关键环节进行了系统布局,计划实施100个重点科研项目,培育5家百亿级企业,形成全产业链协同发展的良好生态。
此次杭州企业研发的模型在国际性竞技中脱颖而出,不仅展现了杭州在人工智能前沿领域的技术实力,也印证了其产业布局的前瞻性与有效性。当全球顶尖的AI模型在真实金融市场中同台竞技时,杭州军团的表现,无疑为这座“数字之城”的人工智能产业发展写下了最生动的注脚。
