
【导读】华为发布AI领域突破性技术Flex:ai,宣布同步开源至魔擎社区
11月21日,华为正式发布AI领域的突破性技术——Flex:ai。在整卡算力无法得到充分利用的AI工作负载场景下,该技术可将算力资源的平均利用率提升30%。
Flex:ai是一款基于Kubernetes(开源容器编排平台)构建的XPU(各种类型处理器)池化与调度软件,与英伟达旗下Run:ai公司的核心技术类似,但具备两个特有优势。
同时,Flex:ai是能够让AI行业化落地的重要工具之一。华为在发布Flex:ai后,会同步开源至魔擎社区,从而构建完整的ModelEngine开源生态。
华为公司副总裁、华为数据存储产品线总裁周跃峰表示,Flex:ai能够释放基础设施潜力,开源加速AI真正走向平民化。

AI时代需要AI容器技术
Flex:ai呈现三方面关键能力
为什么推出Flex:ai?华为方面认为,在大模型时代,容器技术与AI是天然搭档。
容器技术作为一种轻量级虚拟化技术,可以将模型代码、运行环境等打包成一个独立且轻量级的镜像,实现跨平台无缝迁移,解决模型部署存在环境配置不一致的痛点。
同时,容器技术可以按需挂载GPU(图形处理器)、NPU(神经网络处理器)的算力资源,并且按需分配和回收资源,提升集群整体的资源利用率。
第三方机构数据显示,目前AI负载大多已容器化部署和运行,预计到2027年,75%以上的AI工作负载将采用容器技术进行部署和运行。
此外,传统容器技术已经无法完全满足AI工作的负载需求,AI时代需要AI容器技术。
Flex:ai可以大幅提升算力资源的利用率,主要是通过对GPU、NPU等智能算力资源的精细化管理与智能调度,实现对AI工作负载与算力资源的“精准匹配”。
具体来看,Flex:ai的关键能力分别是算力资源切分、多级智能调度、跨节点算力资源聚合。
以算力资源切分为例,Flex:ai可以将单张GPU/NPU算力卡,切分为多份虚拟算力单元,切分粒度精准至10%,实现单卡同时承载多个AI工作负载的效果。

虚拟化与智能调度优势凸显
在AI容器领域,已有多家企业推出不同的产品。相比英伟达旗下Run:ai公司的核心技术,华为认为Flex:ai具备两大独特优势。
一是虚拟化。除了在本地虚拟化技术中实现算力单元的按需切分,Flex:ai独有的“拉远虚拟化”技术,可以不做复杂的分布式任务设置,将集群内各节点的空闲XPU算力聚合形成“共享算力池”。
据华为方面介绍,Flex:ai可为高算力需求的AI工作负载提供充足的资源支撑,也可以让不具备智能计算能力的通用服务器,通过高速网络将AI工作负载转发到远端“资源池”中的GPU/NPU算力卡执行,实现通用算力与智能算力资源的融合。
二是智能调度。Flex:ai的智能资源和任务调度技术,可以自动感知集群负载与资源状态,结合AI工作负载的优先级、算力需求等多维参数,对本地及远端的虚拟化GPU、NPU资源进行全局最优调度,满足不同AI工作负载对资源的需求。
比如,Flex:ai可以帮助优先级较高的AI工作负载,获得更高性能算力的资源支持。在出现算力资源被全部占满的情况下,Flex:ai能直接抢占其他任务资源,确保最重要的任务能够完成。
对于增量训练场景,Flex:ai可以智能感知集群中增量数据的变化,达到一定阈值后会触发数据飞轮。
构建完整ModelEngine开源生态
Flex:ai的发布和开源,助力华为构建完整的ModelEngine开源生态。
华为构建的ModelEngine开源生态,包含此前发布并开源的Nexent智能体框架、AppEngine应用编排、DataMate数据工程、UCM推理记忆数据管理器等AI工具。
公开资料显示,华为推出的ModelEngine作为大模型训练、推理和应用开发的AI平台,可以提供从数据预处理到模型训练、优化及部署的一站式服务。
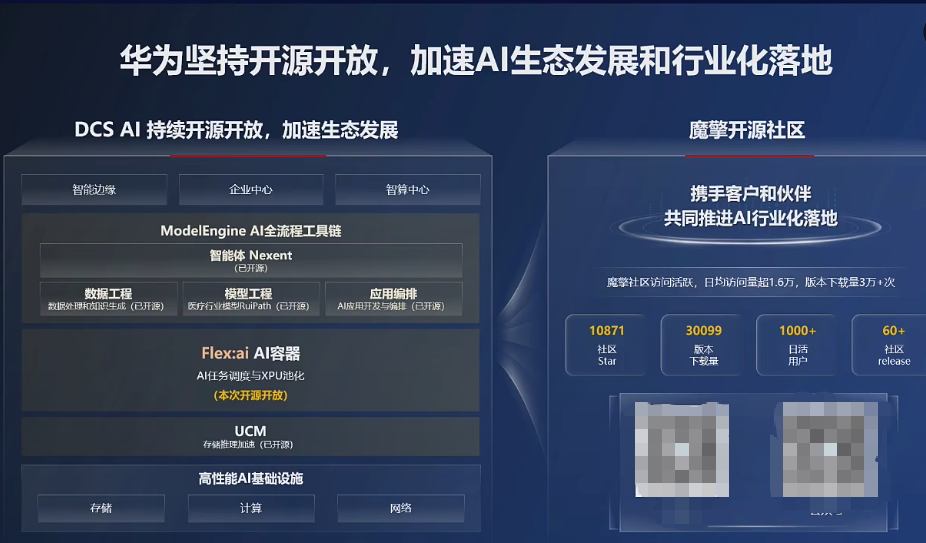
区别在于,华为发布并开源的Flex:ai,可以结合行业场景完成AI容器技术的落地探索。
不同行业、不同场景的AI工作负载差异较大。华为开源的Flex:ai可提供提升算力资源利用率的基础能力,以及部分优秀实践案例,从而与业界一道结合行业场景完成落地探索。
同时,开源的Flex:ai可以在产学研各界开发者的参与下,共同推动异构算力虚拟化与AI应用平台对接的标准构建,形成算力高效利用的标准化解决方案。
