
拉响“红色警报”应对谷歌竞争后,当地时间12月11日,OpenAI推出了GPT-5.2,包含GPT-5.2 Instant、Thinking和Pro模式,此时距离OpenAI更新GPT-5.1只过去了一个月。
此次发布GPT-5.2,被外界视为OpenAI应对谷歌挑战的一次反击。上个月谷歌发布Gemini 3后,在硅谷掀起一场AI权力的重新分配,OpenAI作为大模型霸主的地位受到挑战。
不同于GPT-5.1着重强调具有“情绪价值”、能与人愉快交谈,此次应对挑战,OpenAI拿出了更多“真枪实弹”。GPT-5.2推出了更多智能上的更新,也放出了基准测试的分数。可以看到一些基准测试分数提升明显。
例如,在知识型工作任务GDPval测试中,GPT-5.2Thinking的分数为70.9%,明显超过GPT-5.1的38.8%,在抽象推理ARC-AGI-2基准测试中,GPT-5.2Thinking的分数为52.9%,明显超过GPT-5.1的17.6%。另一些基准测试分数也有提升,在软件工程SWE-Bench Pro、科学问题GPQA Diamond、科学图表类问题CharXiv推理、数学竞赛HMMT测试中,GPT-5.2Thinking的分数为55.6%、92.4%、88.7%、99.4%,GPT-5.1为50.8%、88.1%、80.3%、96.3%。
基于这些能力提升,OpenAI称为专业知识型工作打造的GPT-5.2是公司至今最强的模型,“GPT-5.2在众多基准测试中都刷新了行业水平,例如GDPval测试中,这款模型在涵盖44个职业的明确知识型工作任务中表现超过了行业专家。”
谷歌发布的Gemini 3 Pro此前在基准测试榜单中“屠榜”,OpenAI此次在基准测试榜单中终于扳回一局。
据此前谷歌放出的数据,在ARC-AGI-2测试中,Gemini 3 Pro分数为31.1%,远超GPT-5.1的17.6%,GPQA Diamond测试中,Gemini 3 Pro分数为91.9%,超过GPT-5.1的88.1%,这种明显的能力提升当时引来业内人士预言“未来6个月内很难有公司能超越这一成绩”。此次GPT-5.2在上述两项基准测试中得分终于超过了Gemini 3 Pro。不过,记者留意到,当时谷歌放出的一些分数明显超过OpenAI的基准测试,例如Humanitys Last Exam,此次GPT-5.2并未放出。
OpenAI此次也强调了新模型在专业工作中的可用性,称基准测试得分体现了GPT-5.2在制作演示文稿、电子表格等方面的表现优于或与专业人士持平,生成的电子表格和幻灯片在复杂度和格式呈现上相比前一代有明显提升。不过,用户要使用新的电子表格和演示文稿功能,需要订阅付费套餐。长上下文能力使新模型能处理报告、合同、研究论文等文件。而在编码任务中,GPT-5.2能更可靠地调试生产环境代码、以更少的人工干预完成修复交付。
OpenAI演示了一些编码方面的案例,例如,只需要一个提示,GPT-5.2就能生成一个海浪模拟器、一个节日贺卡生成器。其中,海浪模拟器可以拉动数值,改变风速和海浪高度。OpenAI还强调了GPT-5.2 Thinking的幻觉率低于前一代,在一组去标识的查询中,新模型错误回答的频率比GPT-5.1 Thinking减少了38%。OpenAI称,这意味着在写作、研究、分析和决策中模型犯的错误更少,GPT-5.2 Thinking在图表推理和软件界面理解方面的错误率减少了大约一半。此外,OpenAI称,GPT-5.2 Pro和GPT-5.2 Thinking还是目前最有助于加快科研进展的模型。
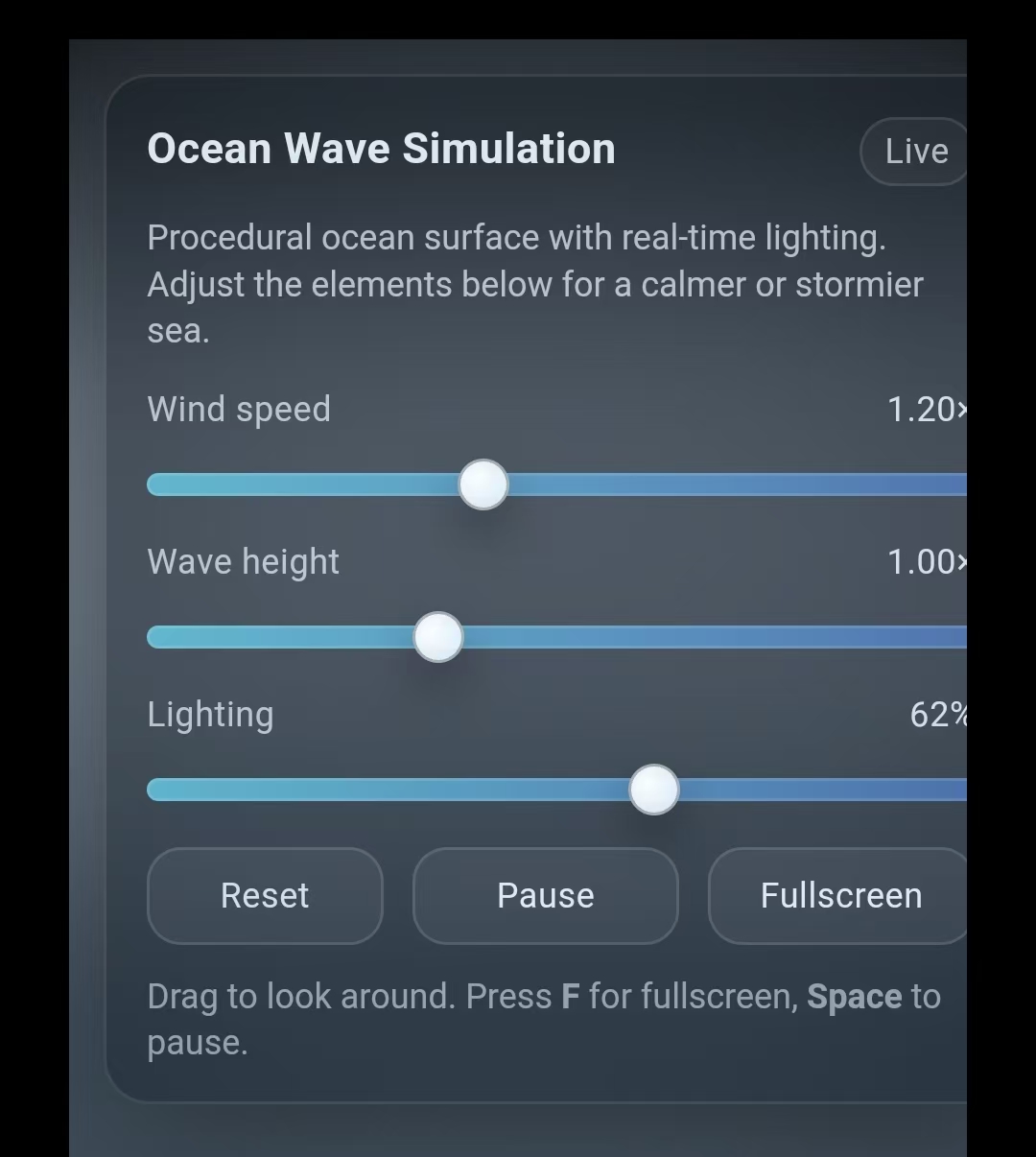
GPT-5.2Instant、Thinking和Pro周四在ChatGPT中陆续推出,付费套餐用户将能率先体验。不过,OpenAI应对谷歌等竞争而拉响的“红色警报”,并未随着GPT-5.2的发布而解除。
此前OpenAI CEO山姆·奥尔特曼(Sam Altman)在内部备忘录中承认,随着谷歌等竞争对手的快速进步,公司正面临“氛围紧张”和“经济逆风”的双重挑战。
此次OpenAI则表示,拉响“红色警报”是为了集中资源,是一种明确优先级的方式,公司确实增加了更多与ChatGPT相关的资源。奥尔特曼表示,谷歌发布的Gemini 3对公司的一些指标的影响,比原本预计的更小,但当竞争对手的威胁出现时,应该专注并迅速应对,OpenAI预计在明年1月之前结束“红色警报”状态。
GPT-5.2将不是OpenAI应对竞争抛出的唯一产品,奥尔特曼在社交媒体上表示,下周OpenAI还将送出一些“小小的圣诞礼物”。
