
连续两次降价后,DeepSeek又在4月28日将限时优惠延长至5月31日。
4月的最后一个周末,DeepSeek先对DeepSeek-V4-Pro(以下简称“V4-Pro”)限时2.5折,再将全系列模型,输入缓存命中的价格降至首发价格的1/10。即在促销期间,V4-Pro输入缓存命中价格从1元/百万tokens跌至0.025元/百万tokens。
此前,国内AI行业正处在涨价周期,大模型公司智谱三度提价,月之暗面新模型的输入和输出价格不同程度上涨,云厂商也动作一致,百度智能云、腾讯云、阿里云调价,理由是同一套:全球算力需求激增,硬件成本上涨。
过去一年,大模型从“价格战”打到“涨价潮”,没人真正赚到钱,营收和净亏损齐涨。DeepSeek用0.025元抛出了一个问题,当推理成本可以被持续压缩,大模型公司的护城河,究竟是更便宜的token,还是更不可替代的价值?
逆行者
DeepSeek的降价来得低调,但并不含蓄。
4月24日,DeepSeek全新系列模型 DeepSeek-V4 的预览版本正式上线并同步开源。该模型按大小分为两个版本:V4-Pro参数较大,1.6T;V4-flash参数284B。两个版本支持的上下文长度都是100万。“从现在开始,1M(100万)上下文将是 DeepSeek 所有官方服务的标配”,DeepSeek特别加粗强调。
当天,DeepSeek公布了两个版本模型的价格,V4-Pro输入(缓存命中)价格1元/百万tokens,输入(缓存未命中)价格12元/百万tokens,输出价24元/百万tokens。同样情况下,V4-flash的价格分别是0.2元/百万tokens、1元/百万tokens和2元/百万tokens。
次日,降价开始,且不止一次。
4月25日,DeepSeek开启 V4-Pro 模型的限时特惠活动,API价格享受2.5折优惠,优惠期限至5月5日。4月26日,DeepSeek全系列模型输入缓存命中的价格降到原价的1/10。
DeepSeek研究员陈德里在社交平台提醒,“输入缓存(命中)的折扣是永久的,折扣促销活动将持续到5月5 日”。
4月28日,DeepSeek又将V4-Pro的2.5折限时优惠,从5月5日延长至5月31日。
按此计算,在5月31日之前,V4-Pro模型百万tokens的输入(缓存命中)价格从原来的1元降到了0.025元。5月31日之后,也只有0.1元。这是DeepSeek这波降价活动中,折扣幅度最大的一项。
何为缓存命中,与缓存未命中有什么区别?
一位头部云厂商工程师向北京商报记者解释,“简单说,缓存命中是指模型‘记得’你之前问过类似的内容,可以直接调用记忆回答不参与推理,收费便宜。缓存未命中相反,意思是模型第一次见这个内容,需要从头算一遍,所以收费贵”。
资本市场快速反应。4月27日,即DeepSeek降价后的第一个交易日,智谱和MiniMax的股价出现不同程度下滑。
0.025元的支撑
这个价格不是凭空出现的。
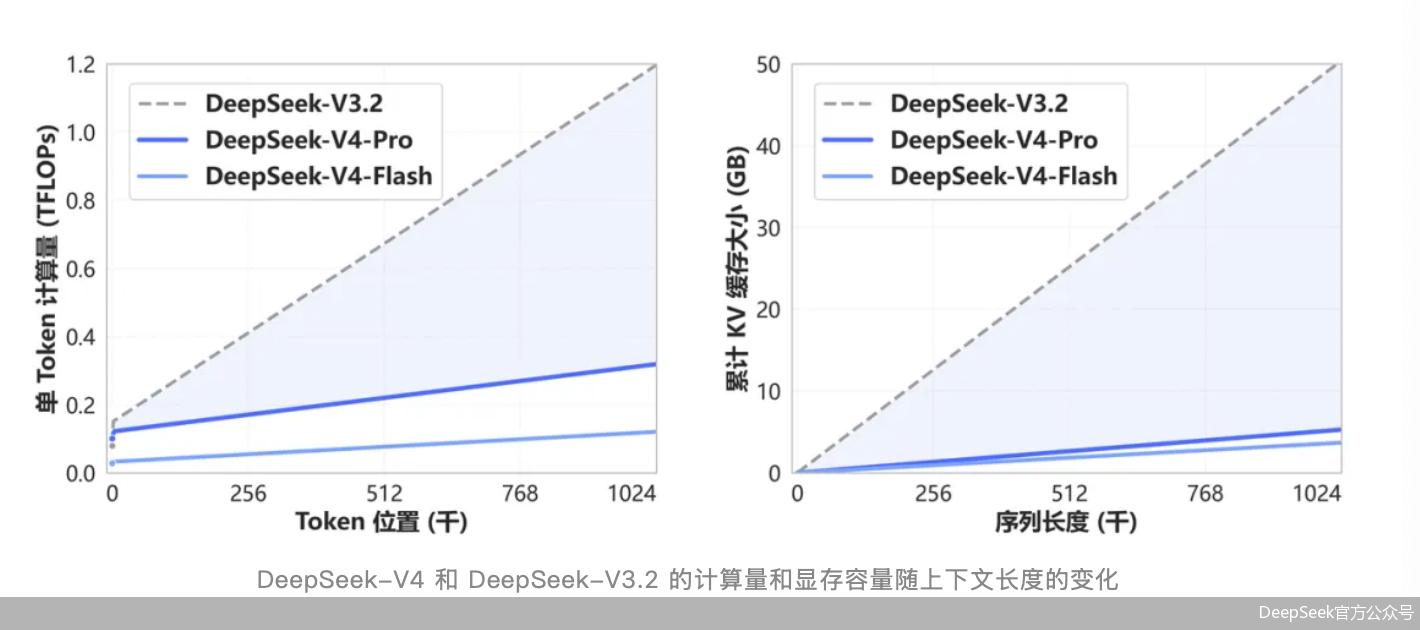
根据官方技术解读,DeepSeek-V4开创了一种全新的注意力机制,在 token 维度进行压缩,结合 DSA 稀疏注意力(DeepSeek Sparse Attention),实现了全球领先的长上下文能力,并且相比于传统方法大幅降低了对计算和显存的需求。
这与外部观察一致。CHIP中国实验室主任罗国昭向北京商报记者分析称,DeepSeek V4降价“更大程度上跟模型算法优化、同等性能的算力消耗降低有关,和定位同样的大模型相比,V4的优势是在更多参数、更高性能情况下的更低价格”。他也谈及硬件成本,但强调“与采购国产芯片只有宏观的相关性,没有直接和实时的关联”。
另一家大模型厂商从业者楚清(化名)则提供了另一种解释:“看上去是DeepSeek在全栈适配国产算力方面领先,所以敢于定低价”。他的观点建立在DeepSeek模型价位表下的一行小字:“受限于高端算力,目前 Pro 的服务吞吐十分有限,预计下半年昇腾950超节点批量上市后,V4-Pro的价格会大幅下调”。
一个值得注意的插曲是,4月24日也就是DeepSeek模型上新当天,华为计算宣布:昇腾一直同步支持DeepSeek系列模型,本次通过双方芯模技术紧密协同,实现昇腾超节点全系列产品支持DeepSeek V4系列模型。
DeepSeek也将华为昇腾和英伟达一起写进DeepSeek-V4技术报告:“我们在英伟达GPU和华为昇腾NPU平台上验证了细粒度EP(专家并行)方案。”
4月28日,摩根士丹利亚太研究团队发布的最新行业报告《China's AI Path: More Bang For The Buck》也提到,中国模型的“性价比”优势集中体现在:以美国同行15%—20%的推理成本实现同等智能水平。报告将工程效率提升归因于三大方向:架构层面的稠密模型与MoE、注意力机制改进;后训练层面的强化学习与模型蒸馏,以及推理基建层面的硬件优化与KV cache(一种缓存机制)效率。新近发布的DeepSeek-V4被视为最新例证。
谁会接招
不过,摩根士丹利还是大幅上调中国两大前沿AI公司目标价,其中,MiniMax目标价由990港元上调至1100港元,行业评级维持“In-Line”,并明确预期,MiniMax在M3模型升级后将启动重大价格上调,这或成为下一阶段ARR(会计收益率)催化剂。
从企业层面看,DeepSeek的降价暂时没有等来同行跟进。
4月28日,北京商报记者就会否跟进降价,采访了智谱、MiniMax、百度智能云、阿里云、腾讯云,截至发稿,以上几家公司相关人士均未回应。
楚清从技术层面解释了这种分化的原因:“其他公司如果没有和国产算力提前优化适配的话,短期内成本降不下来。”
文渊智库创始人王超的判断更聚焦于价格本身的长期趋势:“token降价是技术的进步,否则不可能实现。最近不管是算力、token、芯片、内存的价格都在上涨,处在一个小周期上涨的阶段,但大周期肯定是要下降的。”
作为智能体赛道的一员,猎豹移动董事长兼CEO傅盛更关注另一条路径的可能性。
他在试用V4系列模型后认为,“V4把国产AI大模型,无论开源还是闭源的性能又提高到一个更高的水平,直逼全球最强模型。虽然还有3—6个月差距,但已经足够好用了。更重要的是,DeepSeek可能正在引领国产AI走出一条和美国AI不同的道路”。
这些判断并不矛盾,DeepSeek用技术降本验证大周期下降的方向,而智谱、MiniMax们在用涨价对冲小周期上涨的压力,但从业者都明白核心护城河一定不只是价格这一单一要素,DeepSeek已经给出了它的答案,但行业还在沉默中等待更多人表态。
