
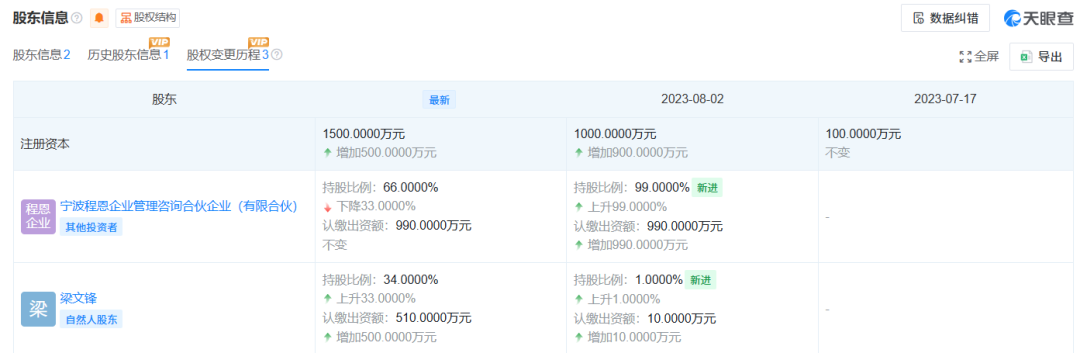
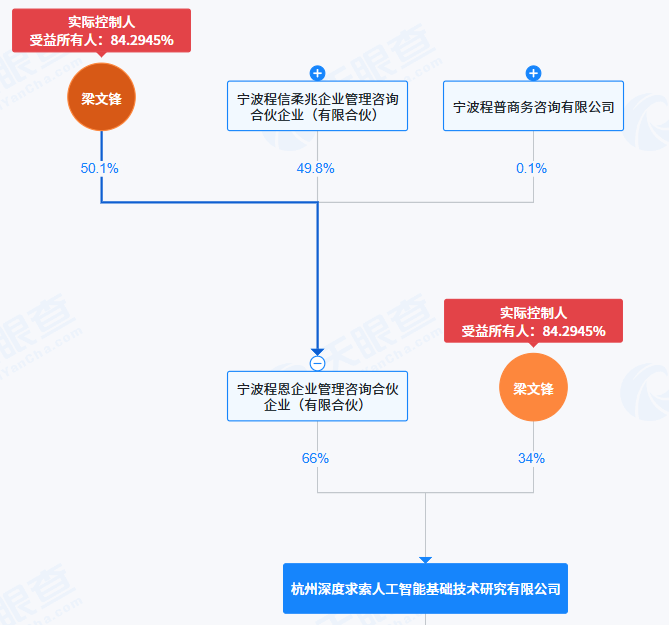
梁文锋持股占比由1%提高至34%。
来源:新财富杂志综合自证券时报、21世纪经济报道、澎湃新闻、界面新闻、第一财经、长安街知事
01
DeepSeek增资
据天眼查信息显示,4月27日,杭州深度求索人工智能基础技术研究有限公司(DeepSeek)注册资本发生变更,由1000万元增加至1500万元,增幅50%。
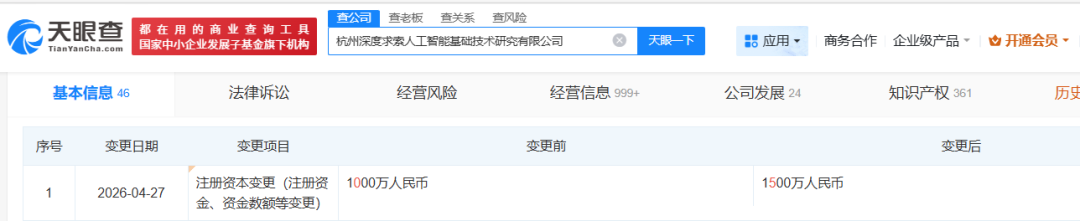
其中,DeepSeek创始人梁文锋认缴的注册资本由10万元增加500万元,达到510万元,直接持股比例由1%升至34%。宁波程恩企业管理咨询合伙企业(有限合伙)持股比例由99%下降至66%。
此次变化后,梁文锋通过宁波程恩企业管理咨询合伙企业(有限合伙)等,以间接、直接方式持有DeepSeek约84.29%股权。
DeepSeek成立于2023年7月17日,总部位于浙江省杭州市拱墅区,是从事大语言模型及多模态AI技术研发的有限责任公司,其推出的DeepSeek系列开源模型,是国内领先的开源大模型系列。
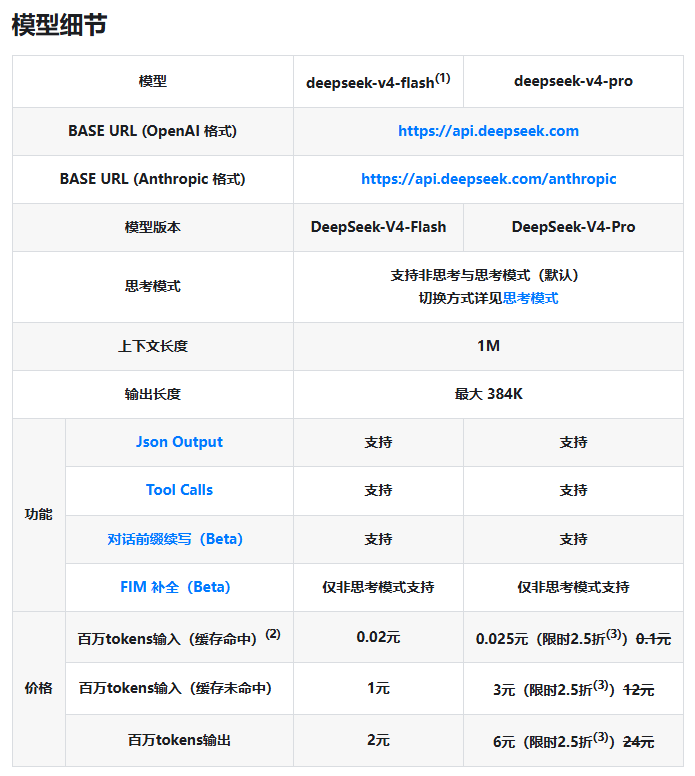
4月24日上午,DeepSeek正式发布全新系列大模型DeepSeek-V4预览版,同步完成开源,并开放官网、App及API调用服务,标志着百万字超长上下文能力进入普惠阶段,自研稀疏注意力架构让推理算力消耗大幅降低,Pro版单token算力仅为V3.2的27%,KV缓存降至10%,引起广泛关注。
4月26日,DeepSeek官方发布API价格调整公告,全系API输入缓存命中价格降至首发价的十分之一,DeepSeek-V4Pro更叠加限时二五折,百万Tokens输入缓存命中低至0.025元,创全球大模型价格新低。
DeepSeek官方API定价页面公示,本次降价覆盖V4系列全模型,核心调整集中在输入缓存命中场景。其中DeepSeek-V4-Flash输入缓存命中价格从0.2元/百万Tokens降至0.02元/百万Tokens。
面向企业级用户的DeepSeek-V4-Pro优惠力度更大,原价1元/百万Tokens的缓存输入降至0.1元,2026年5月5日前叠加二五折限时特惠,实际仅0.025元/百万Tokens,缓存未命中输入从12元降至3元,输出从24元降至6元。
高盛发布分析报告称,DeepSeek-V4的核心意义在于以更低成本支持更复杂的智能体应用落地,从而打开AI应用规模化的新空间。对于纳入昇腾超节点,高盛认为DeepSeek的成本竞争力将进一步强化,为更广泛的应用落地创造条件。
值得注意的是,就在DeepSeek此次增资之前,多次被传出正在寻求募资。
据澎湃新闻4月23日报道,有消息称,腾讯控股和阿里巴巴正洽谈投资DeepSeek。知情人士透露,DeepSeek目前正寻求以超过200亿美元估值筹集资金。不过,有知情人士向澎湃新闻记者明确否认了上述消息,并表示相关传言不实。
而就在此前一周,证券时报4月18日报道,DeepSeek正启动成立以来的首次外部股权融资,以超100亿美元的估值,计划募集不少于3亿美元资金。
上述DeepSeek募资消息,引发巨大关注。公开资料显示,DeepSeek创始人梁文锋从公司诞生第一天就立下铁律:不接受外部融资、不稀释股权、不被任何人的商业化时间表绑架。其底气来自幻方量化。数据显示,2025年幻方量化平均收益率高达56.6%,管理规模超700亿元,每年以数亿元利润支撑DeepSeek的研发消耗。
然而,DeepSeek可能需要更多资金来支撑进一步发展。
近年,DeepSeek人才流失较严重。其95后研究员郭达雅被字节高薪挖走,“AI才女”罗福莉被小米挖走,DeepSeek LLM核心作者王炳宣被腾讯挖走。据公开信息统计,至少5名核心研发人员相继离职,覆盖了基座模型、推理、OCR和多模态四条核心技术主线。此外,今年3月末,DeepSeek连续三天出现大规模服务异常。根据DeepSeek近期发布的招聘岗位,有猜测称,其有意在内蒙自建数据中心。
有观点认为,如果本轮融资能够完成,将有助于DeepSeek推进模型迭代、人才引进以及全球市场扩张。
02
竞争日趋激烈
随着中国AI公司的发展,全球AI格局也在悄然生变。4月13日,斯坦福大学发布《2026年AI指数报告》称,中国的顶级大模型已经基本追上了美国。去年2月,DeepSeek发布的R1模型短暂追平了彼时的美国最强模型。DeepSeek-R1(1400分)仅比当时领先的美国模型o1-2024-12-17(1405分)落后0.4%。此后两国模型多次交替领先。
上述报告还称,当前顶级AI梯队已经高度密集。在参考国际象棋建立的AI等级分系统里,Anthropic、xAI、谷歌、OpenAI、阿里巴巴、DeepSeek,这六家公司的模型已经全部挤进同一个分档,也就意味着这些中美AI领域的“顶级高手”实力非常接近。竞争更多比的已经不是性能,而是向成本、可靠性和特定场景表现转移。此外,按代表性模型数量统计,阿里巴巴、DeepSeek、清华大学和字节跳动均位列全球前十。
据21世纪经济报道,此次降价正值全球大模型厂商竞相以更低价格、更高效率争夺开发者和企业客户之际。随着企业级用户从早期试点转向规模化部署,推理和调用成本已取代单纯模型能力,成为大模型厂商间竞争的重要因素。业内预计,DeepSeek此轮调价将进一步压低同行报价。
花旗在其最新研报指出,DeepSeek-V4-Pro在核心AI性能指标上已与顶尖闭源模型Claude Sonnet 4.6表现持平,同时定价却远低于GPT-5.5。花旗认为,这一现象凸显当前AI大模型赛道中开源模型与闭源领先模型日益加剧的两极分化趋势。得益于极具成本竞争力的底层架构,开源模型在代码生成、智能体工作流及长文本等应用场景中,与闭源巨头的差距正在缩小。
在国产模型阵营内部,Deep Seek-V4-Pro的限时折扣价亦明显低于多数同档位产品。按输出端价格计算,DeepSeek-V4-Pro折扣价为0.87美元/百万Tokens;智谱GLM-5.1、月之暗面Kimi K2.6的输出端报价分别为4.4美元/百万Tokens和4.0美元/百万Tokens,约为其5倍和4.6倍。
根据在全球最大的API聚合平台OpenRouter当前报价,阿里Qwen3.6 Plus输出端约为1.95美元/百万Tokens;MiniMax官方价格显示,MiniMax M2.7输出端为1.2美元/百万Tokens。轻量档位中,阶跃星辰Step 3.5 Flash按OpenRouter报价为0.10美元输入/百万Tokens、0.30美元输出/百万Tokens,输出端与DeepSeek-V4-Flash的0.28美元/百万Tokens较为接近。
记者看到,OpenRouter上,DeepSeek-V4系列模型的调用开始大幅增长,4月26日,DeepSeek-V4-Flash的调用量为814亿Tokens,DeepSeek-V4-Pro的调用量为96亿Tokens,带动DeepSeek在OpenRouter平台的总调用量创近期新高。
目前,DeepSeek已经引发资本市场对其竞争对手的重新定价。4月27日,两大模型厂商股价重挫,MiniMax股价报收750港元/股,跌3.54%;智谱股价报收914.5港元/股,跌2.19%。
此外,DeepSeek近期传出融资消息。有市场消息称,腾讯和阿里正在接触DeepSeek融资事宜,公司估值或超过200亿美元,但具体融资额及估值可能随谈判持续调整。
