
7月23日,夸克健康大模型宣布通过中国 12 门核心学科的主任医师笔试评测,成为国内首个完成这一挑战的大模型,用户在使用夸克的AI搜索查询健康问题时,选择深度搜索可调用夸克健康大模型。继 5 月通过副主任医师职称考试后,健康大模型能力再度向人类医生看齐。
在AI医疗产业规模不断增长的当下,字节、百度、阿里等大厂都在押注健康大模型,市场研究机构Grand View Research的数据显示,全球AI在医疗健康市场的规模预计将从2021年的110亿美元增长至2028年的1940亿美元,年复合增长率超过41%。在这个冉冉升起的新赛道,值得关注的是,各家健康大模型比拼的关键是什么?
“我们判断现阶段健康大模型核心的痛点还是准确性不够。”夸克健康产品负责人姚垚表示,大模型落地应用层面的打造是工程问题,需要时间,但模型能力才是基础的竞争力。
围绕大模型的准确性,面向消费者的健康大模型面临诸多挑战,患者选取的提示词是否准确、多模态能力的建设等都影响大模型答案的输出。武汉大学精神卫生中心主任王惠玲提到,例如在精神科诊疗过程中,能否准确通过病人表达挖掘病症、了解病人需求点等就是一大挑战,AI能否准确理解病人表达甚至帮助医生理解病人,也是健康大模型的一大要点。
从副主任医师到主任医师的能力提升,夸克健康大模型的核心突破之一是构建出“慢思考能力”。夸克健康运营负责人徐健介绍,该能力融合了链式推理与多阶段临床演绎路径建模,驱动模型在面对复杂医疗问题时,能够分阶段、层层深入地推导出最终回答。
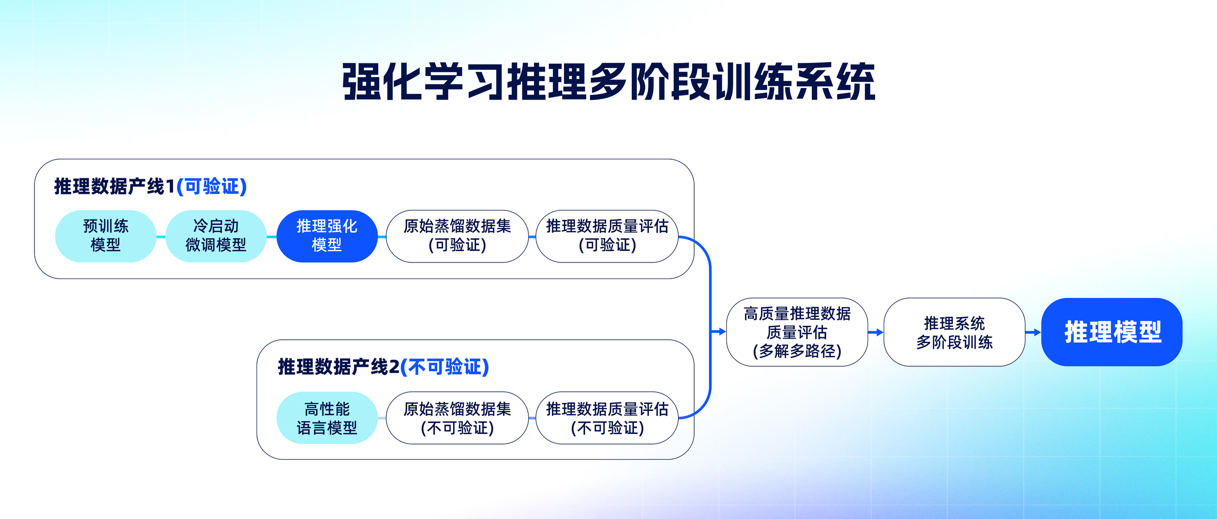
具体来看,要构建慢思考能力首先要有高质量推理训练数据。一方面,夸克将医学数据划分为“可验证”和“不可验证”两类,分别对应诊断类任务和健康建议类任务,另一方面,夸克在训练方法上引入“过程奖励模型”和“结果奖励模型”,分别评估模型推理链的合理性与最终结论的准确性,在这背后,大模型也在进入“思维训练”。“我们不是在训练AI回答医学问题,而是在训练它学会医学思维”,徐健表示。
如何提升健康大模型准确性成为大厂竞赛关键,人类医生的临床数据、诊断乃至数据标注等投入对健康大模型的发展也更加重要。记者了解到,目前夸克健康大模型有千人规模的专业医师标注团队,其中超过400名为副主任医师及以上的高资历医疗专家。但高投入的背后,商业化仍是健康大模型难解的题。
“目前我们还不考虑商业化的事情。”徐健表示,未来,健康大模型的商业化可能包括用户的健康档案管理、诊疗服务的转化,以及智能互联设备的服务都可能成为探索方向,但这仍是个“目前谈起来还太早”的问题。
