
阿里开源全新架构Qwen3-Next,80B参数新模型只需激活3B即可实现旗舰性能。
9月12日,阿里通义发布下一代基础模型架构Qwen3-Next和基于新架构的模型Qwen3-Next-80B-A3B,包含两个版本:更擅长理解和执行指令的指令(Insctruct)模型,以及更擅长多步推理和深度思考的推理(Thinking)模型。
据介绍,相比Qwen3的MoE(混合专家)模型结构,Qwen3-Next进行了以下核心改进:混合注意力机制、高稀疏度MoE结构、一系列训练稳定友好的优化,以及提升推理效率的多token预测机制(简称MTP,Multiple-Token Prediction)。
在核心技术方面,新模型采用全球首创混合架构,75%用Gated DeltaNet(线性注意力),25%用原创Gated Attention(门控注意力),总参数80B只需激活3B,就可以在性能上媲美Qwen3旗舰版235B模型,算力利用率约为3.7%,帮助用户“极致省钱”。
在训练成本方面,Qwen3-Next模型较今年4月发布的密集模型Qwen3-32B大降超90%,长文本推理吞吐量提升10倍以上。新模型在Qwen3预训练数据的子集15T tokens上进行预训练,仅需Qwen3-32B所用GPU计算资源的9.3%,便能训练出性能更好的Qwen3-Next-Base基座模型,大幅提升了训练效率。
阿里通义团队指出,高稀疏MoE架构是Qwen3-Next面向下一代模型的最新探索。当前,MoE是主流大模型都采用的架构,通过激活大参数中的小部分专家完成推理任务。此前,Qwen3系列的MoE专家激活比约为1比16,而Qwen3-Next通过更精密的高稀疏MoE架构设计,实现了1比50的极致激活比,创下业界新高。
在性能表现方面,Qwen3-Next指令模型的性能表现与参数规模更大的Qwen3-235B-A22B-Instruct-2507持平,思维模型表现优于谷歌闭源模型Gemini-2.5-Flash-Thinking。
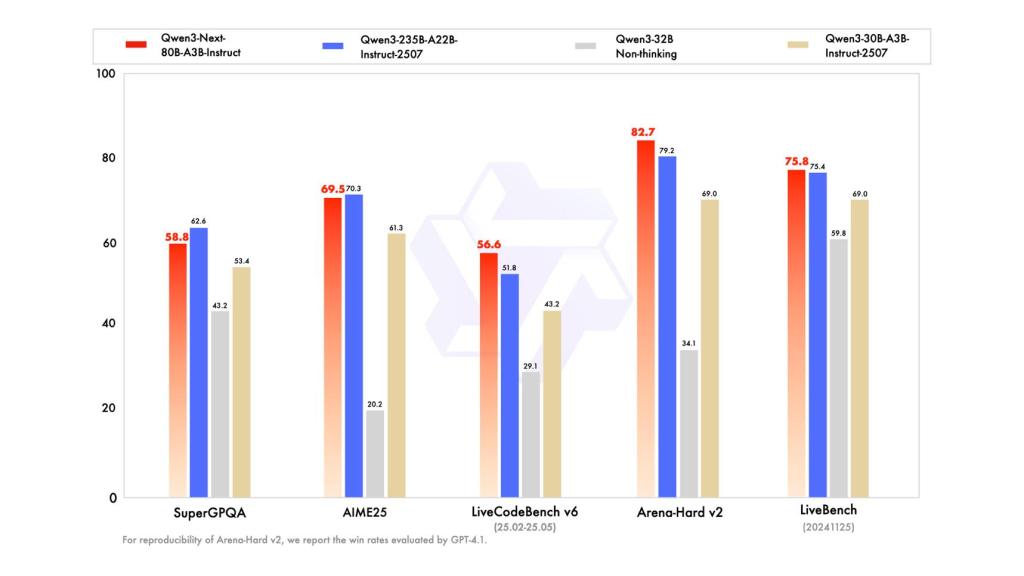
Qwen3-Next-80B-A3B-Instruct指令模型性能评测图。来源:阿里通义
目前,新模型已在魔搭社区和HuggingFace开源,开发者也可通过Qwen Chat免费体验,或直接调用阿里云百炼平台提供的API服务。
关于Qwen3-Next模型值得注意的创新点,Pine AI联合创始人、首席科学家李博杰对澎湃新闻记者表示,Qwen3-Next采用了混合注意力机制和高稀疏MoE架构,从而大幅提升效率;除了这两大创新点以外,Qwen3-Next还在预训练时采用了多Token预测技术MTP(Mutiple-Token Prediction),模型推理速度大幅提升。
李博杰表示,虽然以上三种技术创新在学界已有研究,但阿里证明了其在工业界的实用性,同时还保持了开源:“Qwen3-Next第一次证明了这些技术能够放在一起共同运作,并且能够在实际的业务场景中展现出很好的能力表现。从评测结果和模型架构来看,Qwen3-Next已经达到了谷歌Geimini 2.5 flash的水平。”
近期,阿里通义动作频频,包括推出超万亿参数的Qwen3-Max-Preview、文生图及编辑模型Qwen-Image-edit、语音识别模型Qwen3-ASR-Flash等。全球AI开源社区HuggingFace的最新数据显示,通义千问Qwen衍生模型数已超17万,稳坐全球第一开源模型。
9月1日,国际权威市场调研机构沙利文(Frost&Sullivan)发布了最新的《中国GenAI市场洞察:企业级大模型调用全景研究,2025》,报告显示,中国企业级大模型调用呈爆发式增长,2025年上半年日均调用量较2024年底实现363%的增长,目前超10万亿Tokens。其中,阿里通义占比17.7%位列第一,是中国企业选择最多的大模型。
